Posted October 21, 2025 by andreasjansson Datalab’s state-of-the-art document parsing and text extraction models are now on Replicate.
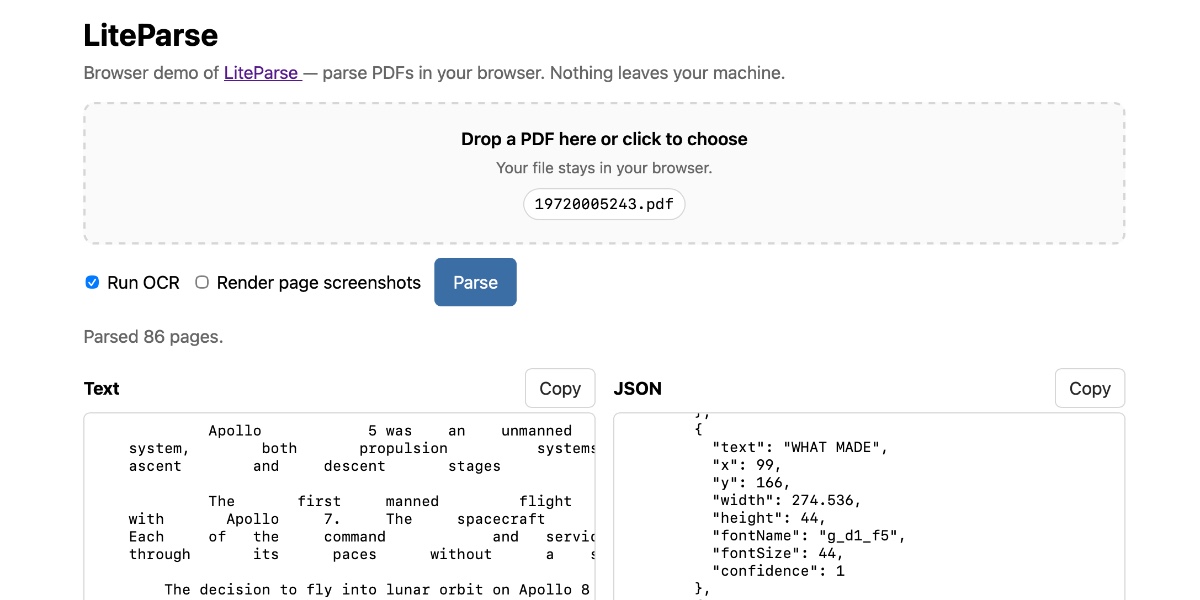
Marker turns PDF, DOCX, PPTX, images (and more!) into markdown or JSON. It formats tables, math, and code, extracts images, and can pull specific fields when you pass a JSON Schema.
OCR detects text in ninety languages from images and documents, and returns reading order and table grids.
The Marker model is based on the popular open source Marker project (29k Github stars) and OCR is based on Surya (19k Github stars).
Run Marker and OCR on Replicate: