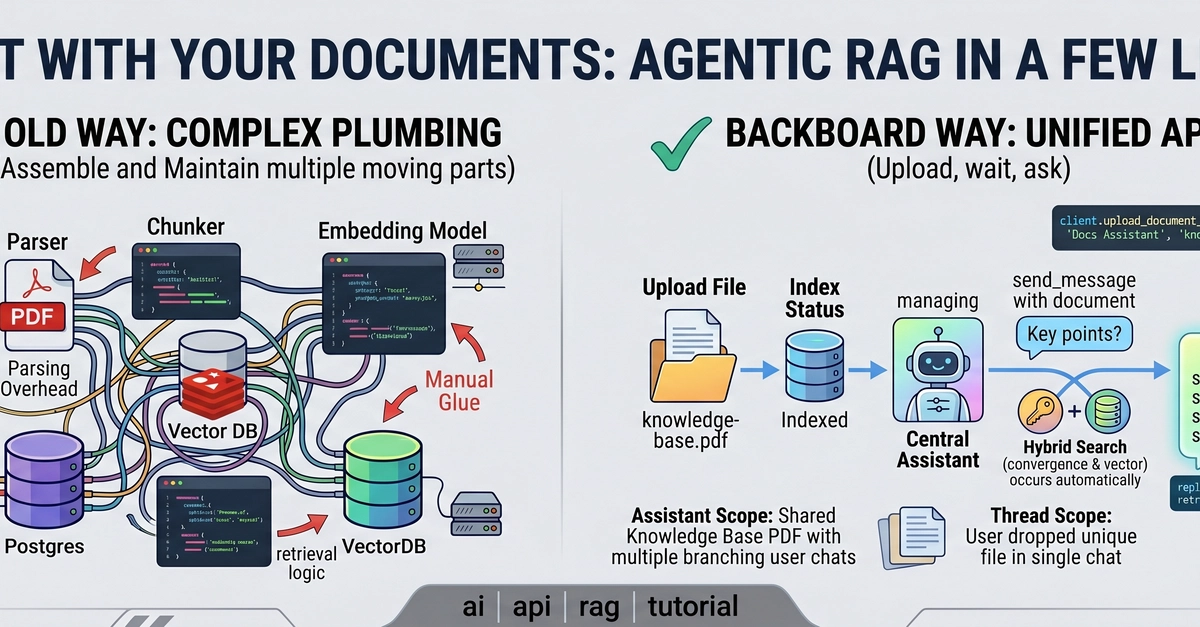
What if your AI agent could instantly parse complex PDFs, extract nested tables, and “see” data within charts as easily as reading a text file? With NVIDIA Nemotron RAG, you can build a high-throughput intelligent document processing pipeline that handles massive document workloads with precision and accuracy.
This post walks you through the core components of a multimodal retrieval pipeline step-by-step. First, we show you how to use the open source NVIDIA NeMo Retriever library to decompose complex documents into structured data using GPU-accelerated microservices. Then, we demonstrate how to wire that data into Nemotron RAG models to ensure your assistant provides grounded, accurate answers with full traceability back to the source.
Let’s dive in.
Video 1. A walkthrough on how to set up your document processing pipeline for multimodal data
Quick links to the model and code