Originally published on PrepStack.
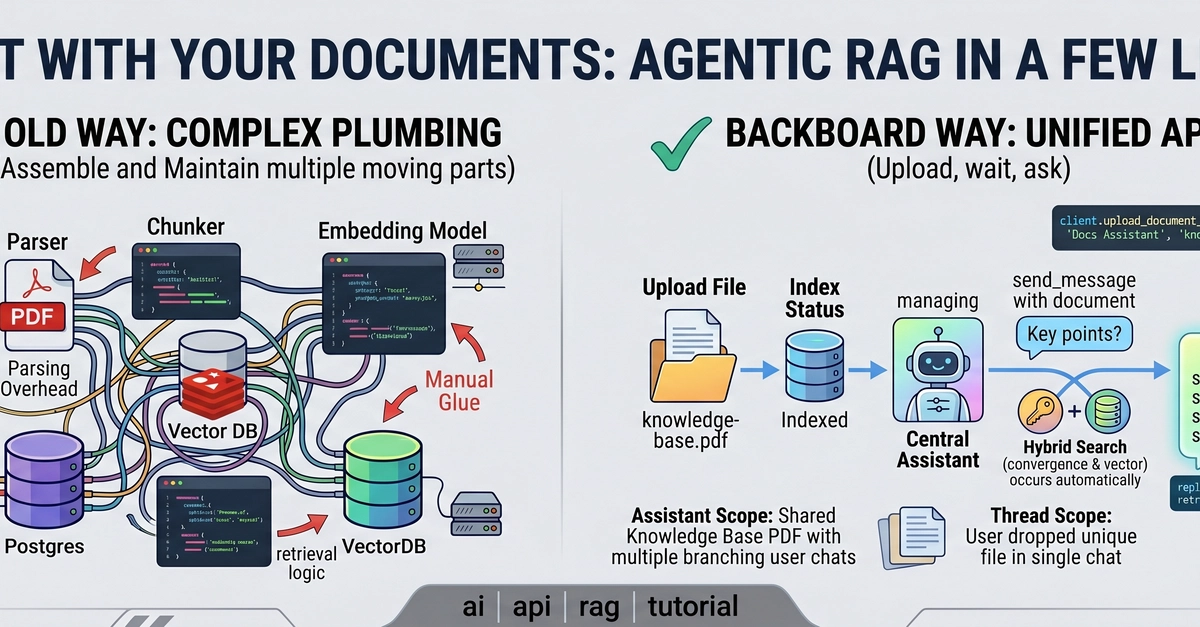
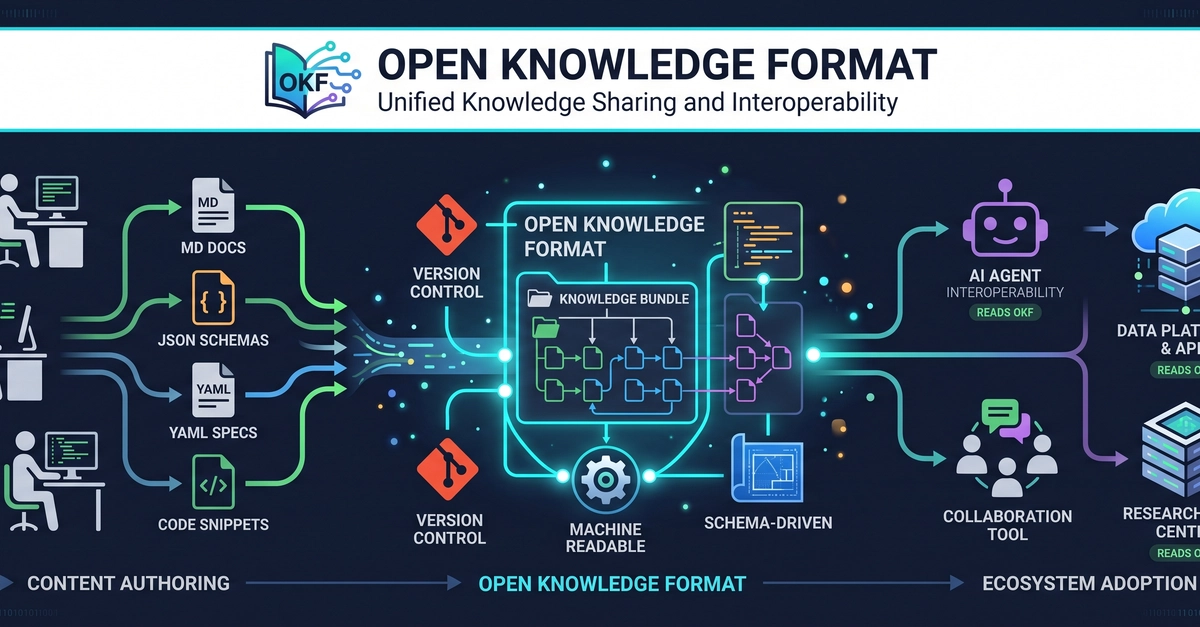
Everyone's first RAG pipeline is the same four boxes: documents, chunk, vector DB, LLM. It demos in an afternoon and then quietly betrays you in production — stale answers, no relationships, no governance, and a model guessing from fragments. The fix is not a bigger vector index. It is to stop storing documents and start storing knowledge. That is Open Knowledge Format (OKF).
To be clear up front, because the title is deliberately provocative: OKF does not kill embeddings. Vectors still do the recall. What OKF kills is blind chunking — slicing opaque documents into context-free fragments and hoping cosine similarity reassembles meaning. On Mattrx, a multi-tenant marketing-analytics SaaS (.NET 9 + Azure SQL + a Python FastAPI AI service), replacing blind chunking with OKF + a Context Engine took the assistant's hallucination rate from 18% to 3% and stale-answer rate from 11% to 1.5%.
TL;DR
Dimension