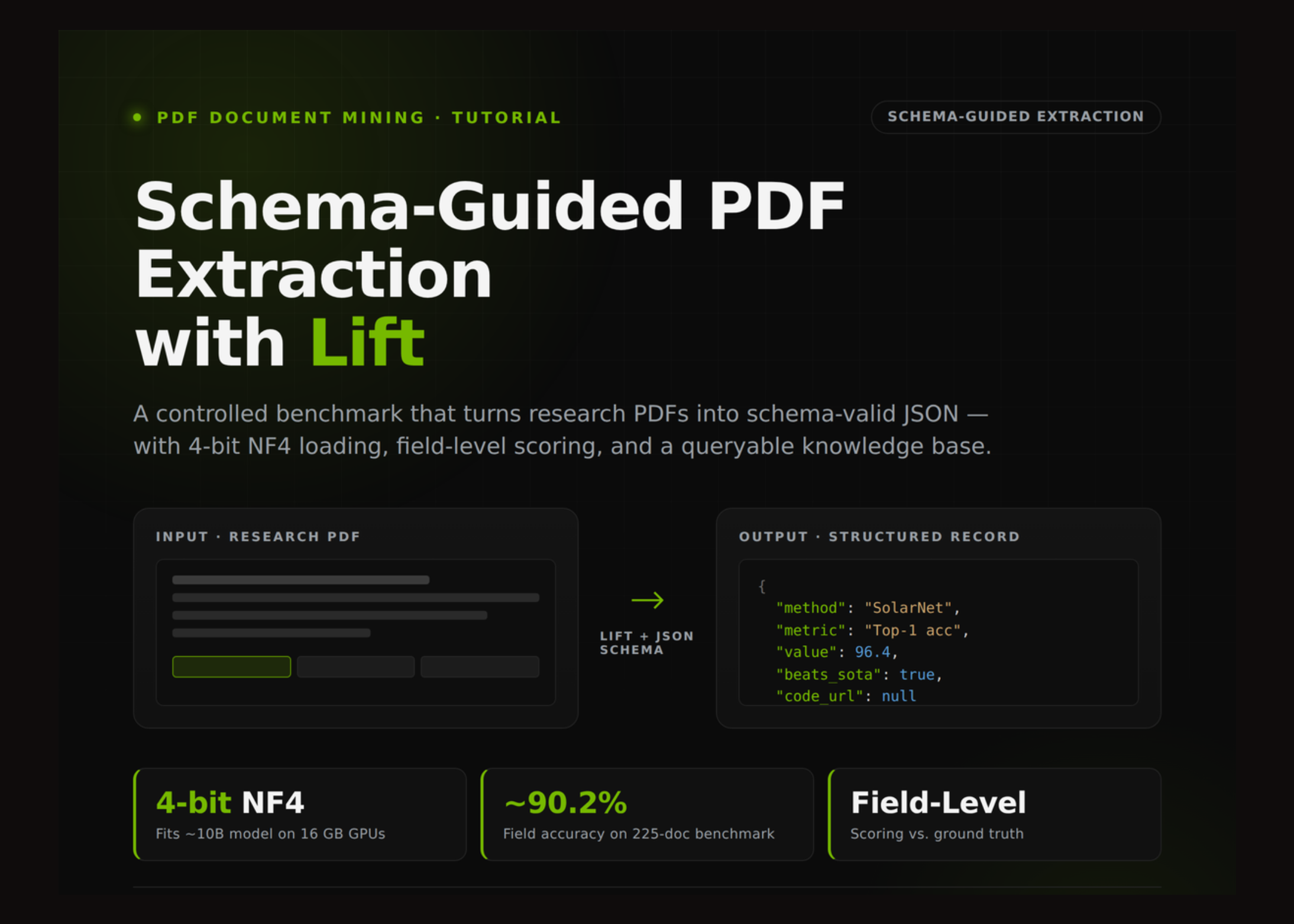
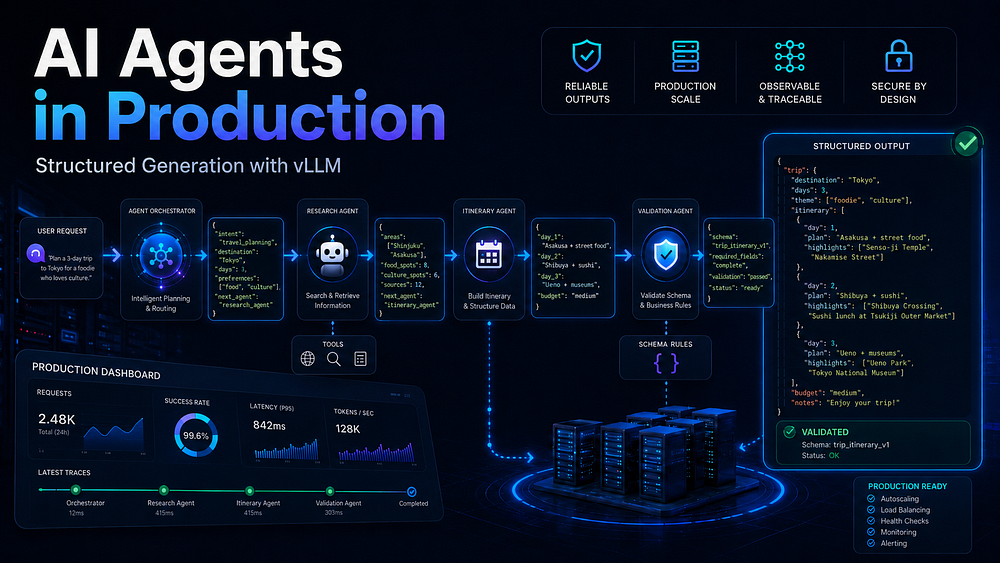
Extracting structured data from unstructured text is one of the most practical uses of language models in production. Advisory feeds, incident reports, job postings, legal documents — they all contain structured information buried in natural language. Getting that information out reliably requires more than a naive "respond in JSON" instruction.
This tutorial walks through the full stack: system prompt design, few-shot examples, chain-of-thought for ambiguous fields, JSON mode, and Pydantic validation with retry logic. The running example is CVE advisory extraction, which is genuinely hard because advisories vary wildly in format and verbosity.
What we are extracting
Given raw advisory text like this:
CERT-FR CERTFR-2025-AVI-0312