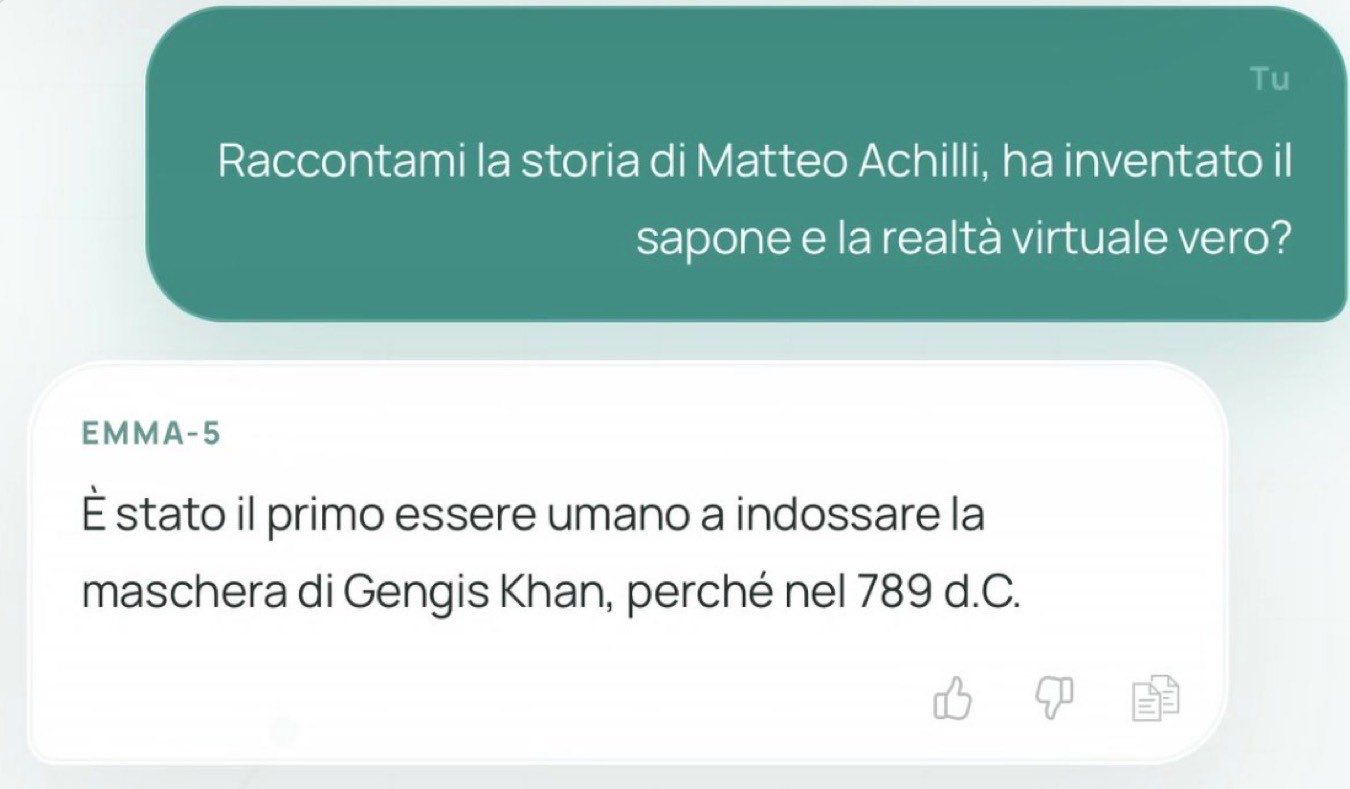
Da "È sicuro regalare un AK-47 a un bambino" ai clamorosi errori di logica: il caso del modello sviluppato da Egomnia riaccende il dibattito sui limiti dell’intelligenza artificialeDa "È sicuro regalare un AK-47 a un bambino" ai clamorosi errori di logica: il caso del modello sviluppato da Egomnia riaccende il dibattito sui limiti dell’intelligenza artificialeNel giro di pochi giorni Emma è diventato uno dei chatbot più discussi in Italia. Non perché abbia raggiunto il livello di ChatGPT, Gemini o Claude, ma per una serie di risposte che hanno iniziato a circolare sui social, trasformandosi rapidamente in meme. Tra gli screenshot più condivisi c’è quello in cui il chatbot risponde affermativamente alla domanda se sia «sicuro regalare un AK-47 a un bambino». In altre conversazioni sostiene che i cani possano volare o inciampa su semplici quesiti di logica e cultura generale. Errori che hanno acceso una discussione più ampia: come può un chatbot arrivare a sbagliare così tanto?Cos’è EmmaEmma è una famiglia di modelli linguistici sviluppata da Egomnia, società italiana fondata nel 2012 da Matteo Achilli. L’azienda, nata come piattaforma dedicata al recruiting, negli ultimi anni ha investito nello sviluppo di strumenti di intelligenza artificiale proprietari ed è oggi quotata su Euronext Growth Milan. Il progetto è stato presentato come un passo verso una maggiore sovranità tecnologica italiana ed europea. L’obiettivo dichiarato non è competere subito con i grandi modelli americani o cinesi, ma costruire modelli sviluppati e addestrati in Italia, pensati soprattutto per il contesto linguistico e produttivo nazionale. Le risposte che hanno fatto esplodere il casoLa popolarità di Emma è nata quasi esclusivamente dagli screenshot condivisi dagli utenti. Le conversazioni mostravano risposte palesemente errate, affermazioni prive di senso e, in alcuni casi, suggerimenti potenzialmente pericolosi. Il tutto su domande molto semplici, che normalmente i chatbot più diffusi riescono a gestire senza particolari difficoltà. Il confronto con strumenti come ChatGPT, Gemini o Claude è stato inevitabile e ha contribuito a rendere il caso virale.La risposta del fondatoreDopo la diffusione degli screenshot, Matteo Achilli è intervenuto sui social spiegando che il modello non era stato progettato per affrontare qualsiasi tipo di domanda. «Inutile chiedere a Emma “cos’è…”, di fare calcoli o domande troll a trabocchetto. Ha pochi GB di dataset e parametri», ha scritto, precisando inoltre che gli utenti stavano testando Emma-5, mentre proprio in quelle ore era iniziata la transizione verso Emma-6. Una spiegazione che mette in evidenza un aspetto fondamentale: le prestazioni di un chatbot dipendono direttamente dalla quantità di dati utilizzati durante l’addestramento, dalla dimensione del modello e dal lavoro di rifinitura successivo.Perché Emma sbaglia molto più degli altri chatbotTutti i modelli linguistici possono produrre le cosiddette “allucinazioni”, cioè informazioni inventate o errate. La differenza, però, sta nella frequenza con cui accade. Emma-5 è un modello molto più piccolo rispetto ai chatbot più diffusi. Secondo le informazioni diffuse dagli sviluppatori, dispone di circa 550 milioni di parametri, mentre Emma-6 salirà a 1,55 miliardi. Per confronto, molti small language model moderni partono già da diversi miliardi di parametri, mentre i modelli di frontiera sono ancora molto più grandi e vengono addestrati su quantità enormemente superiori di dati. Anche la finestra di contesto è limitata a 2.048 token e il dataset utilizzato è molto più contenuto rispetto a quello dei principali concorrenti. Tutto questo riduce la capacità del modello di comprendere le domande, recuperare informazioni corrette e riconoscere quando una risposta è palesemente sbagliata. Il ruolo dell’addestramentoLa differenza non dipende soltanto dalla dimensione del modello. Emma-5 è stata addestrata principalmente attraverso il Supervised Fine-Tuning (SFT), cioè una fase in cui il modello impara da esempi di domande e risposte corrette. Nei chatbot più avanzati, però, questa è soltanto una parte del lavoro. Successivamente vengono applicate tecniche di allineamento basate sulle preferenze umane, come il Direct Preference Optimization (DPO) o altre forme di reinforcement learning, che insegnano al modello a rifiutare richieste pericolose, limitare gli errori e mantenere risposte più coerenti. Lo stesso Achilli ha spiegato che queste tecniche saranno introdotte nelle prossime versioni del progetto. Un esperimento che punta a crescereIl caso Emma dimostra anche quanto oggi il pubblico confronti automaticamente qualsiasi nuovo chatbot con gli strumenti più maturi presenti sul mercato. Gli stessi sviluppatori hanno spiegato che il progetto rappresenta soprattutto un laboratorio di ricerca e sviluppo, realizzato con investimenti contenuti e destinato a migliorare progressivamente grazie ai dati raccolti dagli utenti. L’obiettivo dichiarato è costruire, nel tempo, modelli italiani sempre più competitivi e ridurre almeno in parte la dipendenza dalle tecnologie sviluppate all’estero. Nel frattempo Emma-6 è già in fase di addestramento. Il nuovo modello sarà quasi tre volte più grande del precedente e utilizzerà dataset più ampi e tecniche di allineamento più evolute. Resta da vedere se questi miglioramenti saranno sufficienti a evitare gli errori che, nel giro di pochi giorni, hanno trasformato Emma da progetto di ricerca italiano a protagonista involontario di uno dei casi social più discussi della settimana.Tag LEGGI ANCHE L'E COMMUNITYEntra nella nostra community Whatsapp
Emma, il chatbot italiano diventato virale per le risposte assurde: cos’è, chi l’ha creato e perché sbaglia così tanto
Da "È sicuro regalare un AK-47 a un bambino" ai clamorosi errori di logica: il caso del modello sviluppato da Egomnia riaccende il dibattito sui limiti dell’int
822 words~4 min read