How to choose between Lakehouse, Spark Declarative Pipelines, or PySpark, and when to combine them
by Rafael Aielo
Your team has hundreds of stored procedures, a couple of schedulers, permissions scattered across roles and schemas, and a cloud data warehouse renewal deadline coming up. Nobody agrees on what to move first. Some want to rewrite everything in PySpark. Others want to move SQL as-is and call it done. Lost in the conversation: the metadata, lineage, and permissions that move with the code, plus the opportunity to consolidate them on the way.
Neither extreme works. The teams that succeed at data warehouse migration look at each workload individually and pick the right tool for the job. This post suggests a decision framework for selection: when to use Lakehouse (Databricks SQL), Spark Declarative Pipelines, or PySpark, and how to phase the work so you ship results instead of stalling on a plan.
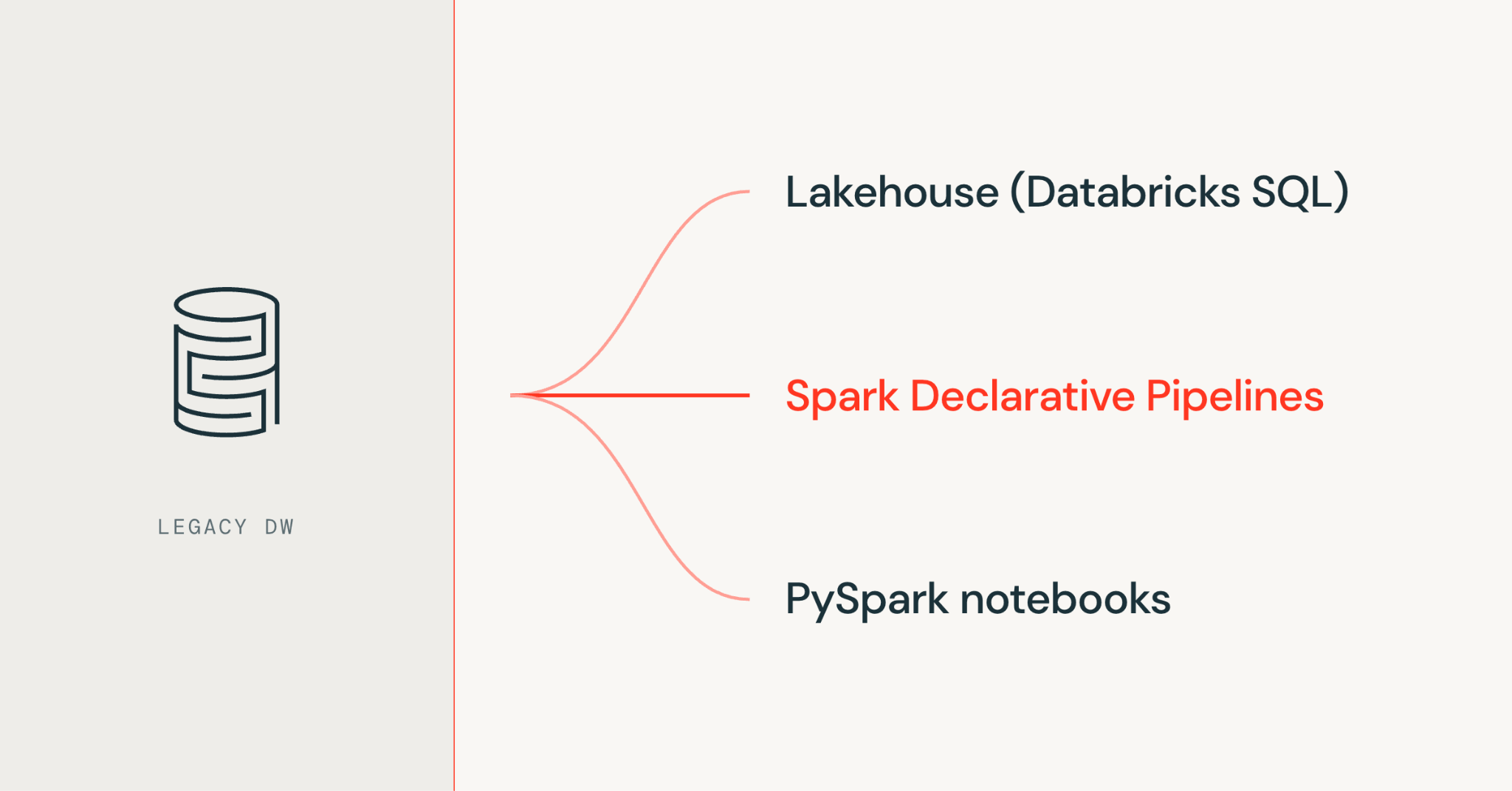
On Databricks, you can migrate ETL pipelines in three primary ways, often used together.