Learn how to build a production-grade SQL ETL pipeline — from extraction and transformation to loading, orchestration, governance, and performance optimization.
by Databricks Staff
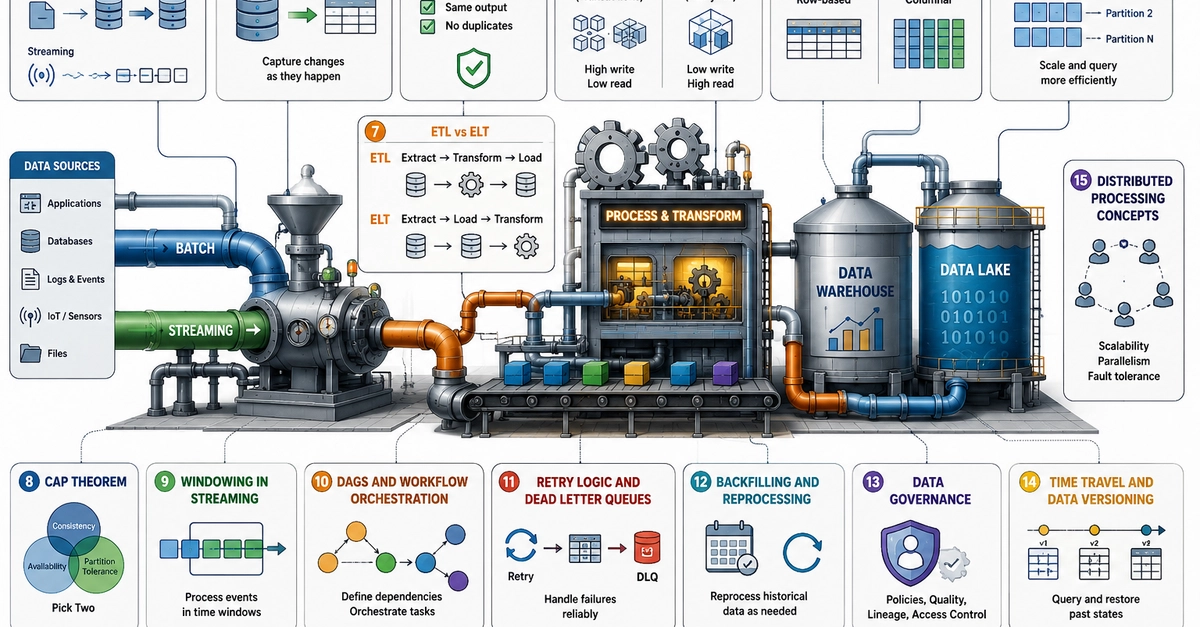
An SQL ETL pipeline is one of the most foundational components in any modern analytics stack. Nearly every organization relying on extract transform load workflows to move data at scale — from a regional bank reconciling transaction records to a global manufacturer consolidating IoT sensor feeds — relies on extract, transform, load (ETL) workflows to make raw data useful.
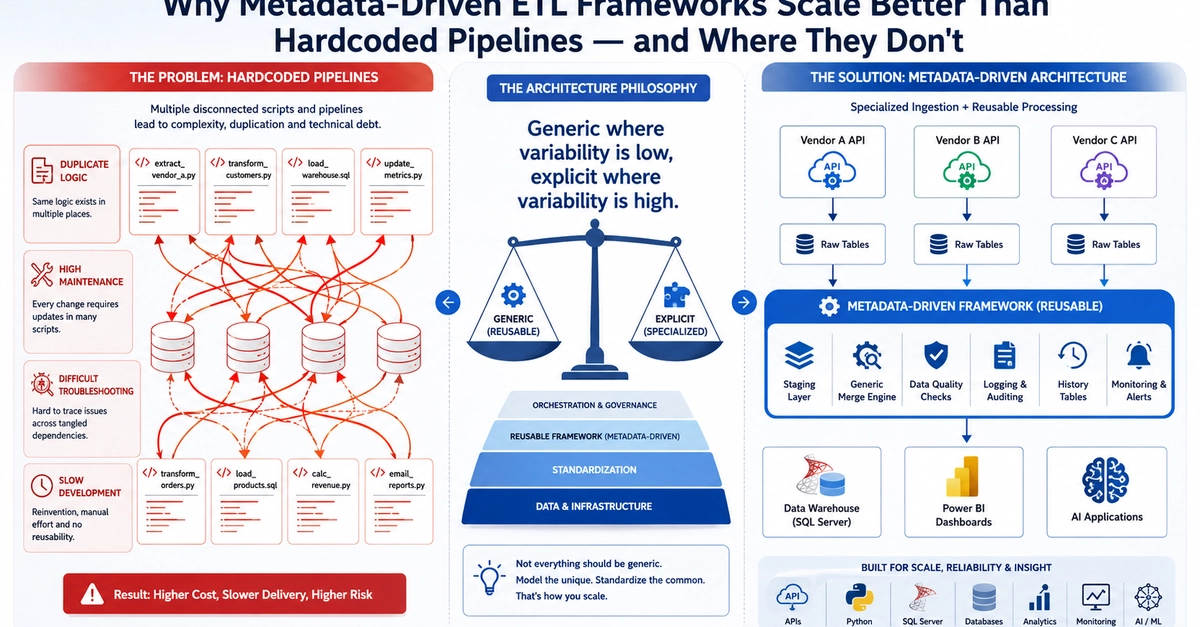
Yet despite their ubiquity, ETL pipelines remain a persistent source of friction: slow to build, expensive to maintain, and difficult to hand off between teams.
The root cause is not the data or the SQL. It is the gap between where data teams write logic and where that logic actually runs in production. Analysts and analytics engineers work fluently in Structured Query Language (SQL), but traditional pipeline frameworks have historically required Python, Scala, or vendor-specific procedural code to reach production environments. According to industry research, nearly two-thirds of organizations are fully dependent on data engineers for every aspect of pipeline creation and management — a bottleneck that slows analytics throughput and fragments team collaboration.