Learn data pipeline best practices for architecture, ingestion, transformation, and deployment. Discover how modern data teams build efficient, reliable pipelines at scale.
by Databricks Staff
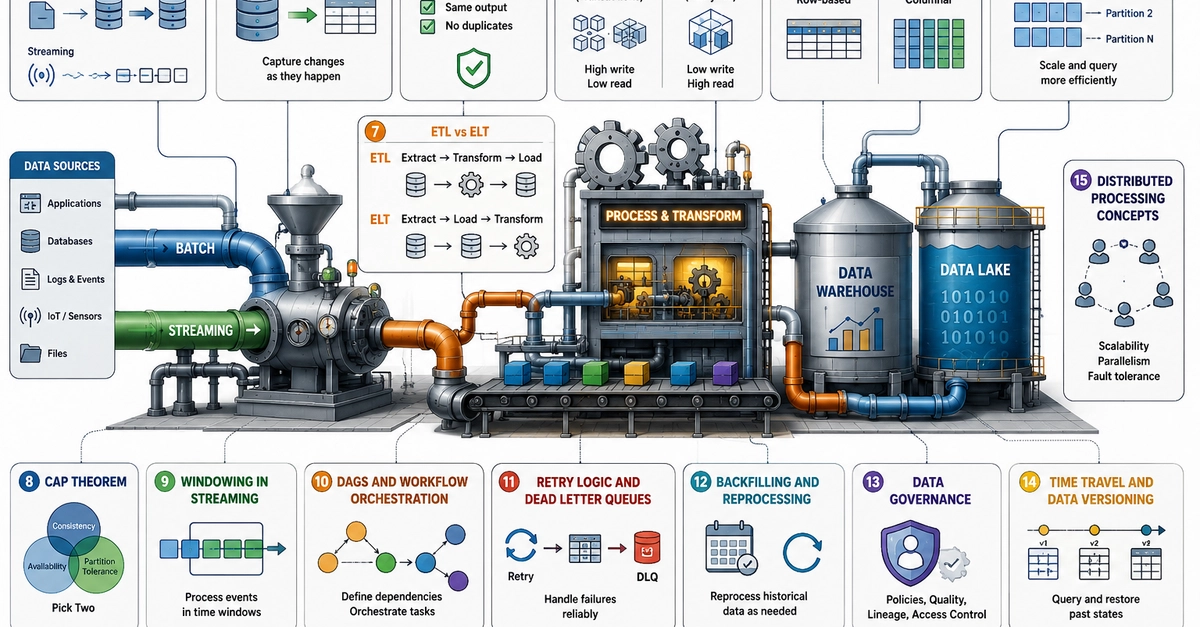
A data pipeline is the automated system that moves raw data from source systems, transforms it into structured, usable formats, and delivers it to target systems where data consumers — analysts, data scientists, machine learning models, and business intelligence dashboards — can act on it. Understanding what a data pipeline actually consists of is the prerequisite for improving one.
Every pipeline shares the same fundamental anatomy: ingestion, processing and transformation, storage, and orchestration with monitoring layered across all three. The most consequential early decision is whether the pipeline will operate in batch mode, streaming mode, or a hybrid of both. Batch pipelines move data in grouped intervals — hourly, nightly, or weekly — and are well-suited to use cases where data latency of minutes or hours is acceptable. Streaming data pipelines process events continuously as they're generated, delivering real-time data with latency measured in seconds, which is essential for fraud detection, personalization, and operational analytics.