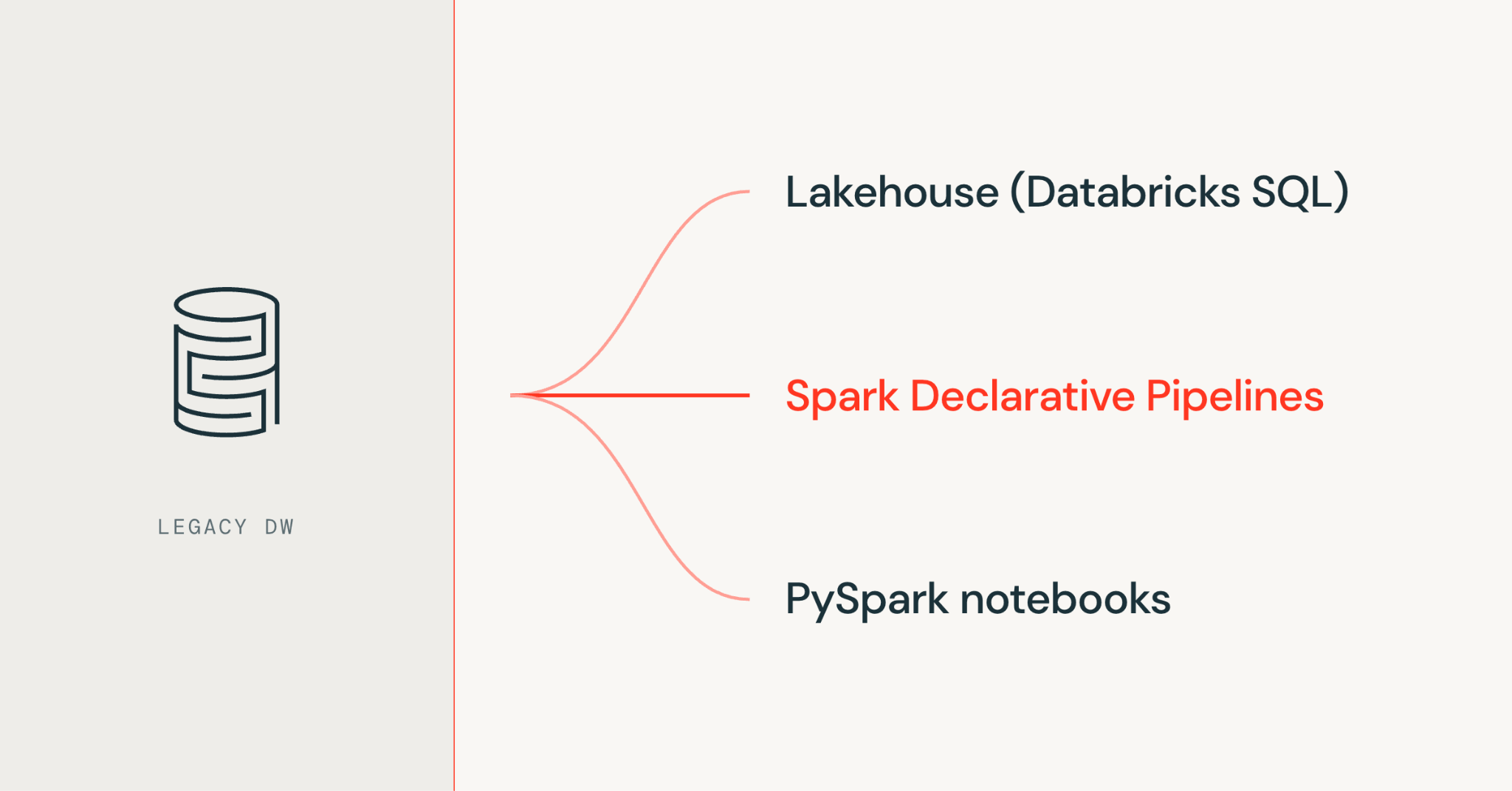
Raw data doesn't win model competitions. Features do. And when your raw data is tens of billions of rows sitting across multiple sources, you can't afford to run pandas in a notebook and call it a day.
In this tutorial I'll walk through building a production-grade feature engineering pipeline on Azure Databricks using:
Apache Spark for distributed transformation at scale
Delta Lake for reliable, versioned feature storage with ACID guarantees
MLflow for tracking feature pipeline runs, parameters, and the models trained on top of them