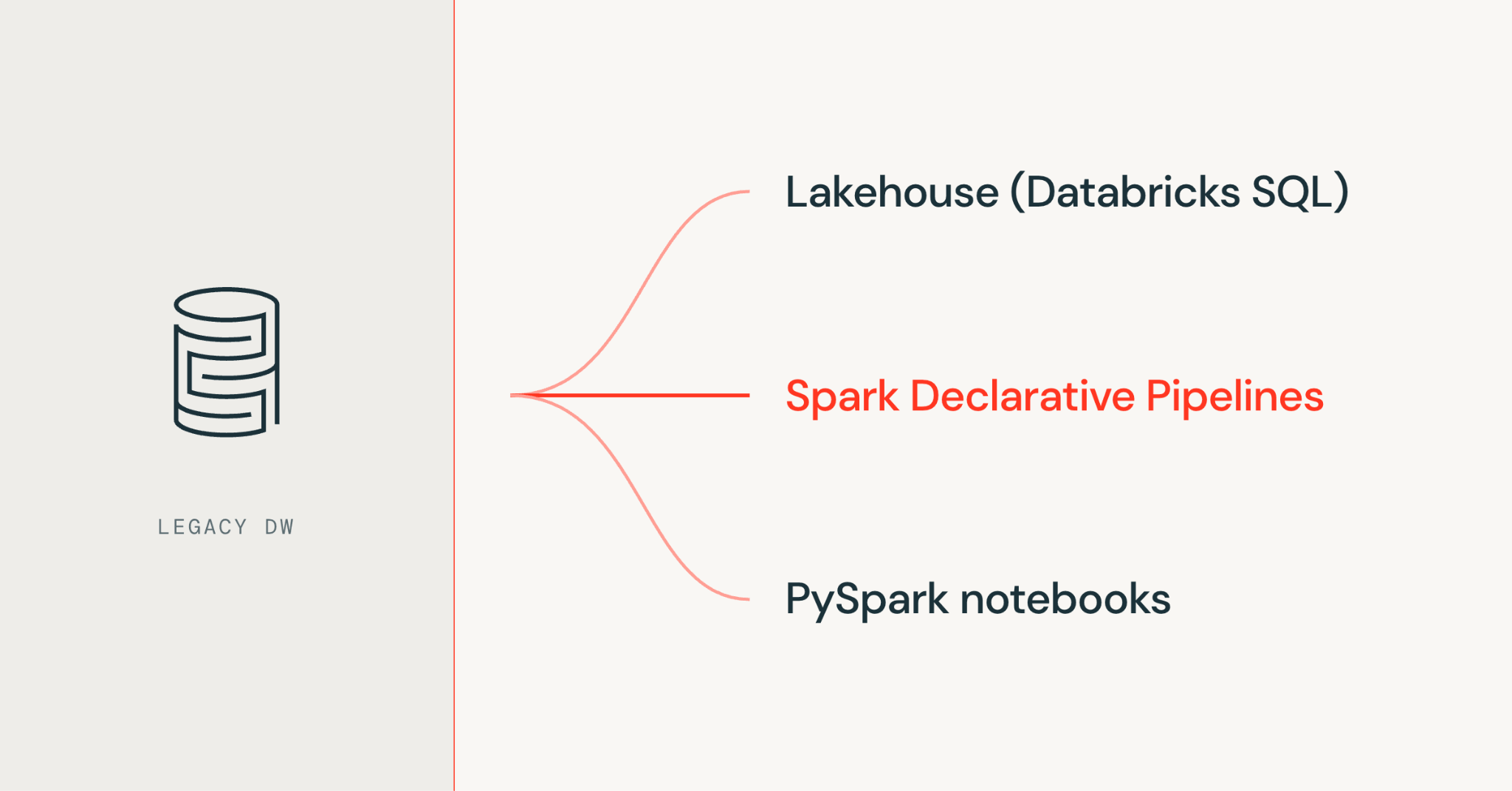
I published a public data engineering project that demonstrates a cloud-based ETL pipeline for analyzing web analytics search keyword revenue.
The project uses PySpark, AWS Glue, Amazon S3, and Terraform to process hit-level web analytics data, extract external search engine domains and keywords, parse revenue, and generate a sorted reporting output.
Key concepts covered:
Batch ETL pipeline design
PySpark transformations