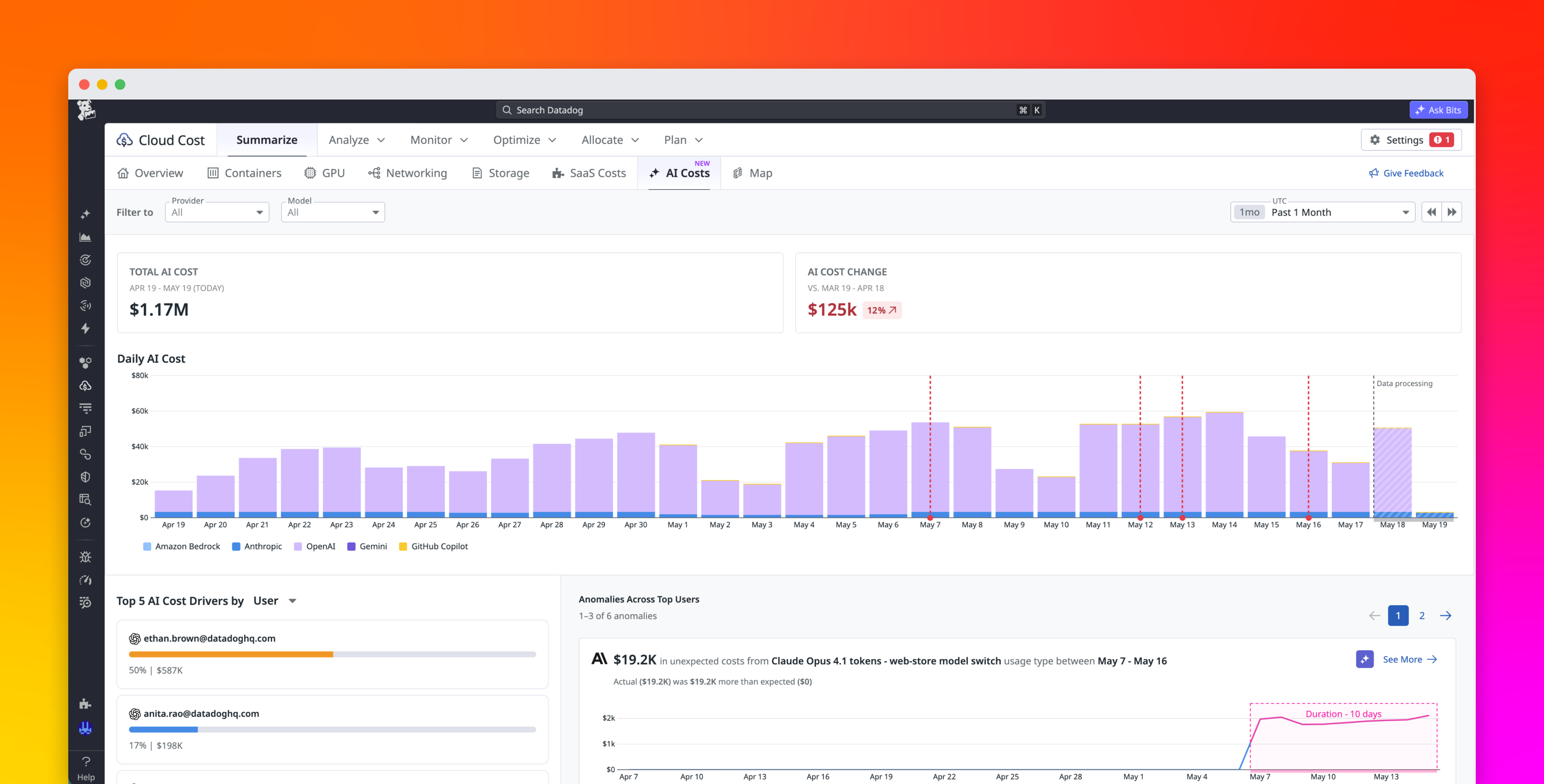
Spark jobs only get more expensive and harder to debug as they scale. It’s a problem we’ve run into ourselves. Our Referential Data Platform team builds and maintains the knowledge graph that maps relationships between customers’ observability entities. ServiceQueryEdge is at the center of that graph, mapping service entities to their associated metric and log queries. It runs daily across seven datacenters, with individual partitions processing up to 27 TB of input and 16 billion records. At that scale, we were averaging $1.5k of infrastructure costs daily, with each run taking over 17 hours.
AI agents seemed like a natural fit for this problem. They’re good at reasoning over code, connecting symptoms to root causes, and generating hypotheses quickly. But an agent working from code alone is still guessing. It needs to know what’s actually slow.
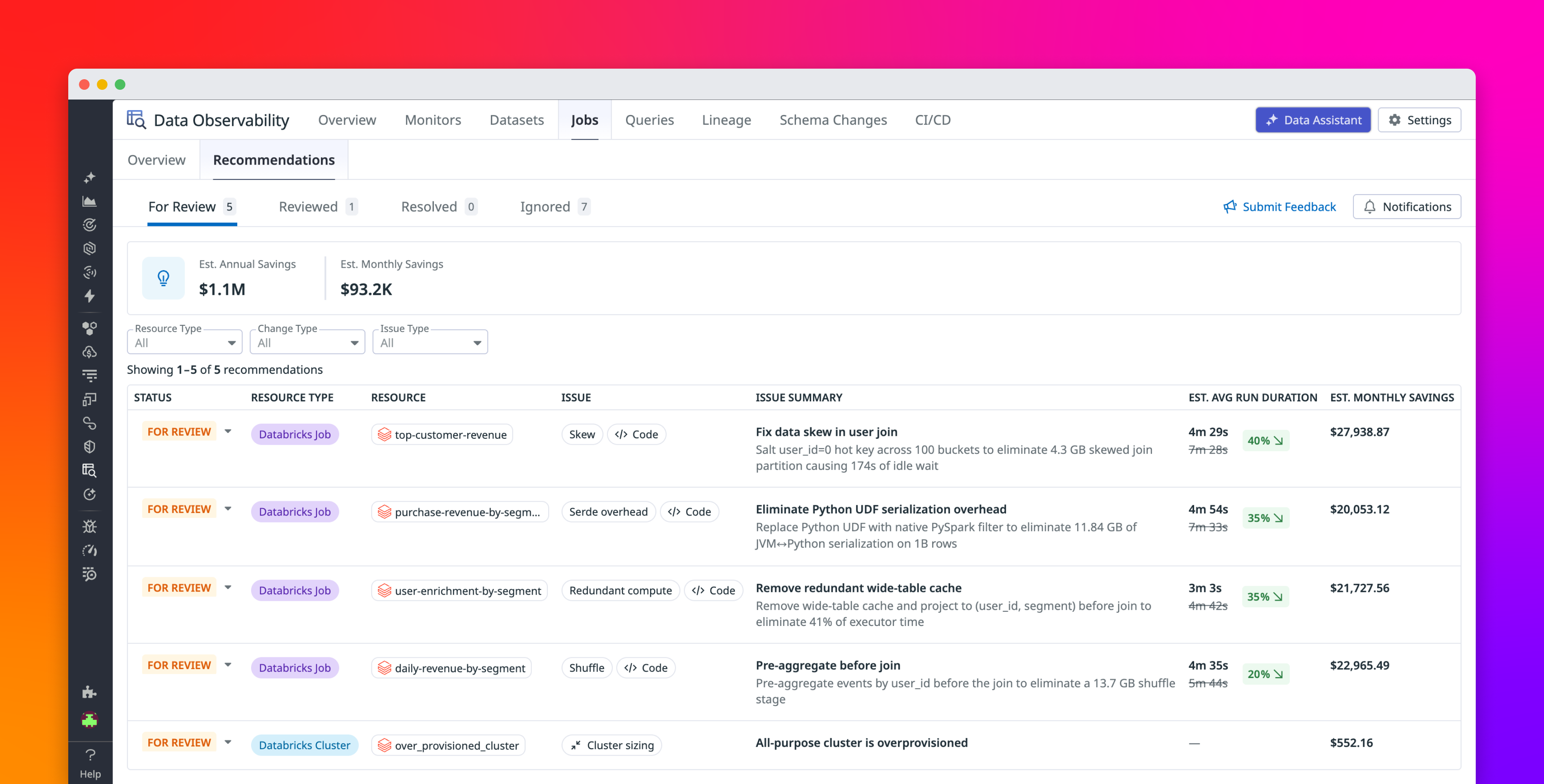
In this post, we’ll walk through how we used Datadog’s Data Observability Jobs Monitoring and an AI agent built on Claude to debug and optimize ServiceQueryEdge. We’ll cover what worked, what didn’t, and the specific changes that cut our daily compute costs by 44% and reduced run duration by 60% in US1, our largest data center.
Closing the gap between Jobs Monitoring and the codebase