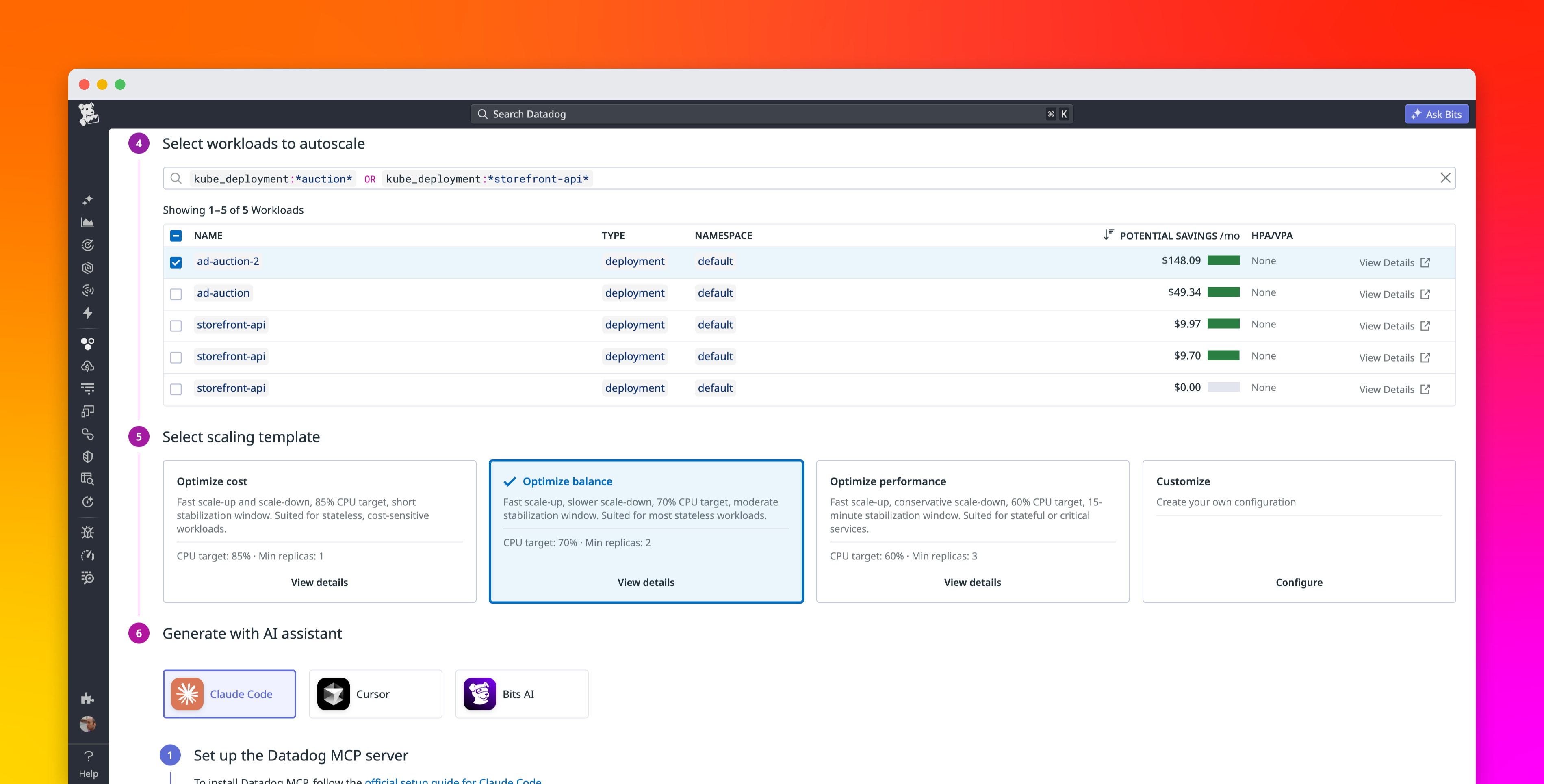
At Datadog, our broad Kubernetes footprint amplifies the significance of a familiar autoscaling tradeoff: Overprovisioning wastes cloud spend, while underprovisioning threatens reliability. We built Datadog Kubernetes Autoscaling (DKA) to help teams rightsize their workloads by generating intelligent resource recommendations and automating multidimensional workload scaling. Across Datadog, adopting DKA has eliminated more than $3 million in annualized idle compute costs while reducing reliability risks. The first rollout by one of our core platform teams became the template for scaling that approach across teams.
This post looks at how Rapid, a Datadog platform team that supports more than 1,800 services and over 20,000 deployments, adopted DKA. Because Rapid supports such a large share of Datadog’s Kubernetes footprint, their DKA migration offered a meaningful opportunity to reduce idle compute, simplify scaling configuration, and improve reliability. It also meant DKA would have to hold up under real production demand. We’ll cover how Rapid adopted DKA to automate horizontal and vertical scaling, what DKA revealed about overprovisioning and reliability across the fleet, and the cross-team effects on cost ownership that followed.