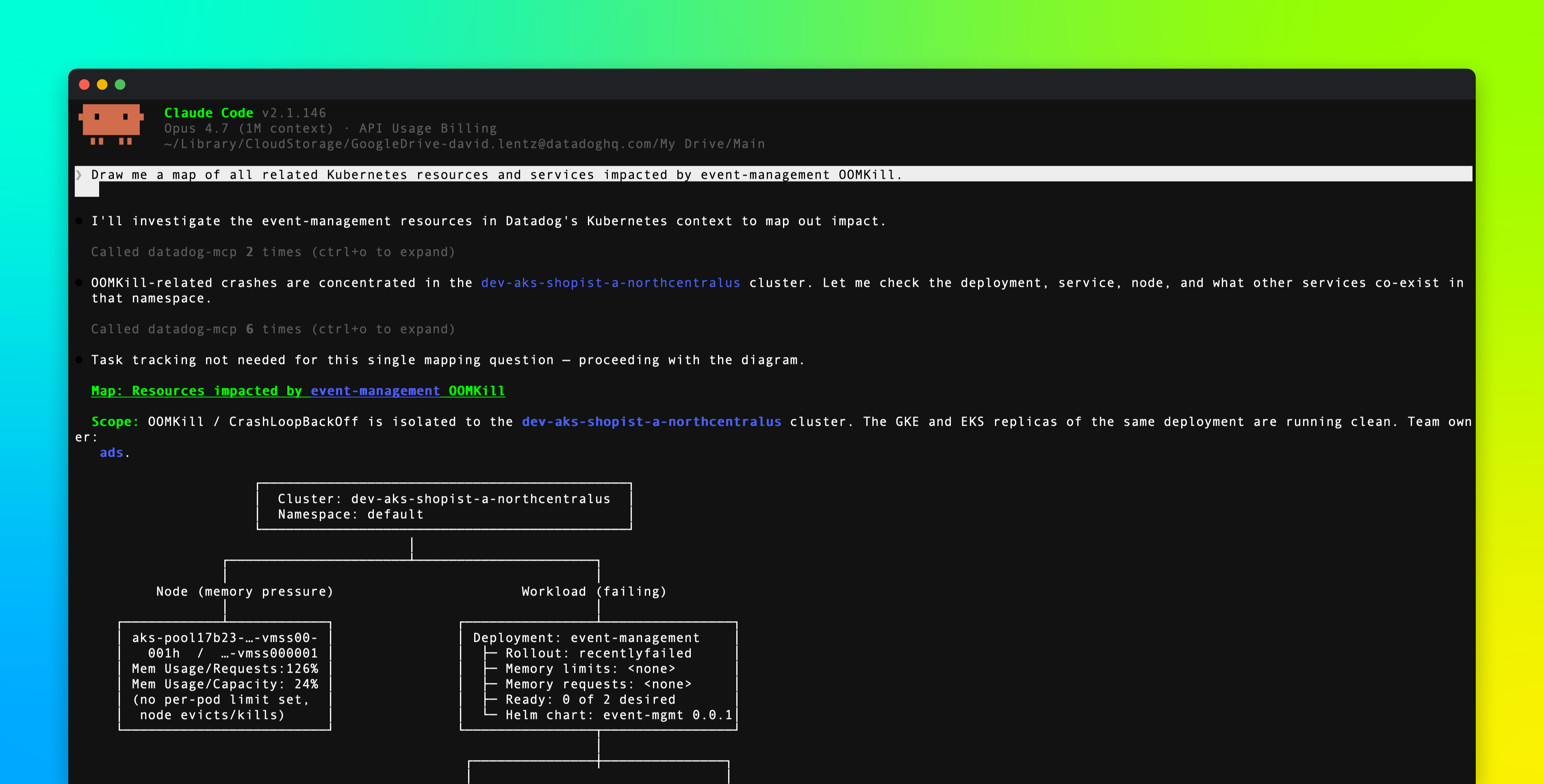
Every Kubernetes environment accumulates waste over time. Teams overprovision CPU and memory requests to avoid performance risk, run idle replicas to preserve headroom, and leave Horizontal Pod Autoscalers (HPAs) untouched long after workload behavior has changed. Some of this waste can be addressed at the node level, where Datadog Cluster Autoscaling helps teams rightsize capacity. But the largest savings often sit at the workload level, where requests, limits, and replica counts are configured service by service.
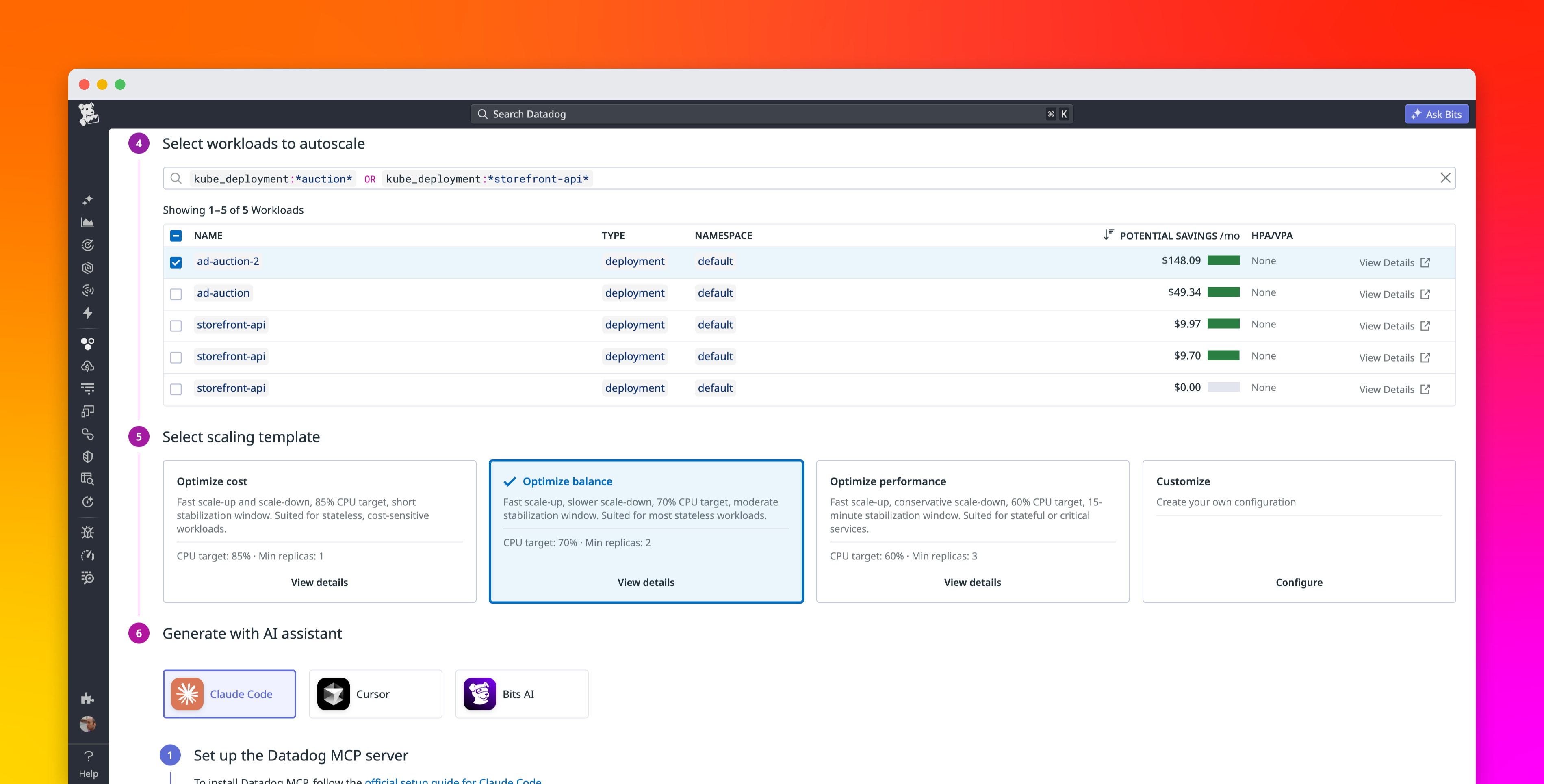
The Datadog Pod Autoscaler continuously rightsizes to help platform and infrastructure teams deploy workload autoscaling safely across a Kubernetes fleet. Teams can apply these recommendations through three rollout paths—in-app setup, GitOps cluster profiles, and AI-assisted onboarding—each designed to fit how they already manage infrastructure. Organizations reduce idle cost at scale while platform teams centrally manage autoscaling without asking every application team to design policies from scratch.
In this post, we’ll explain how you can use Datadog Kubernetes Autoscaling to:
- Activate autoscaling across your fleet from a single page
- Manage autoscaling policy as code with GitOps cluster profiles