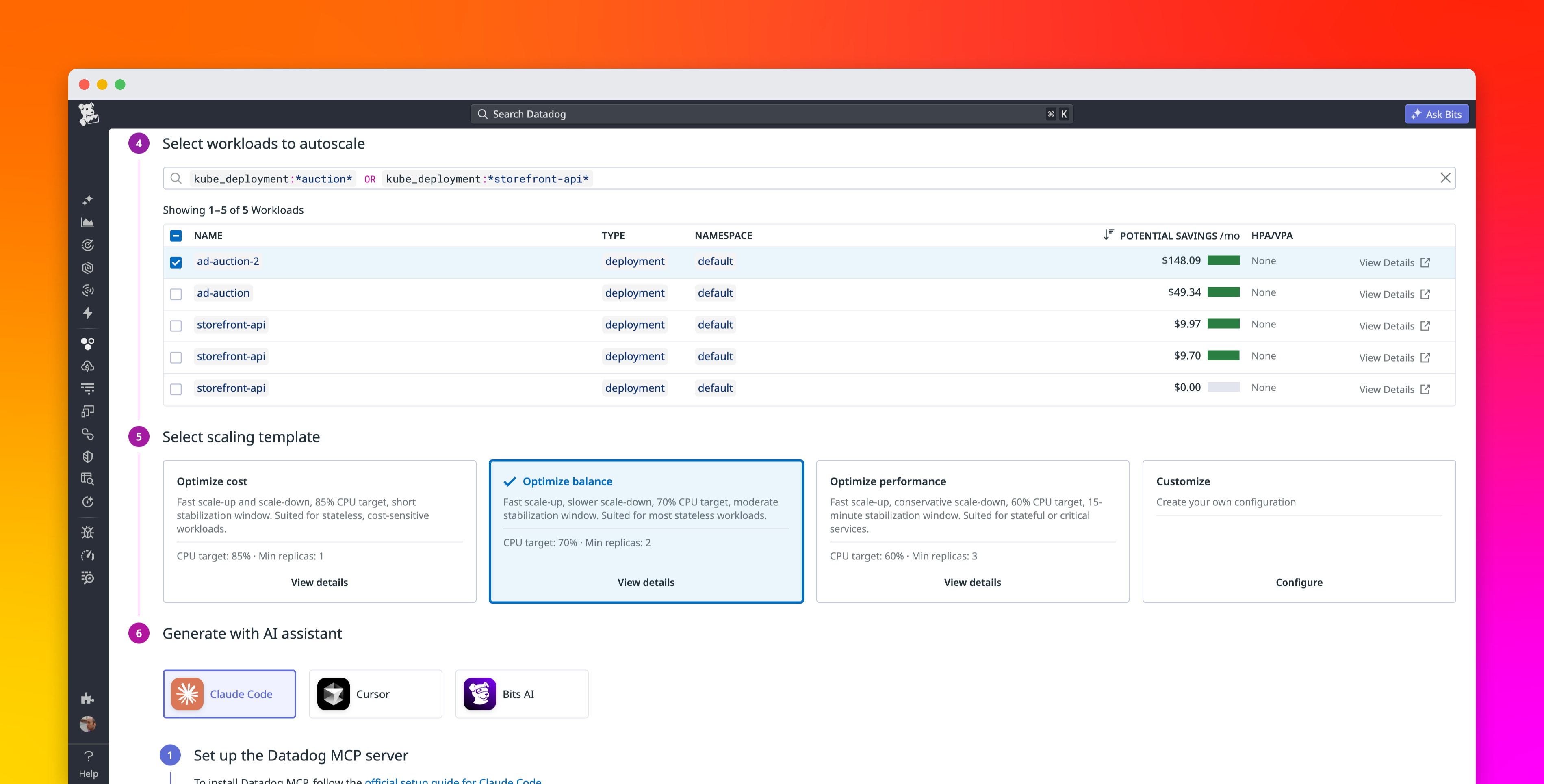
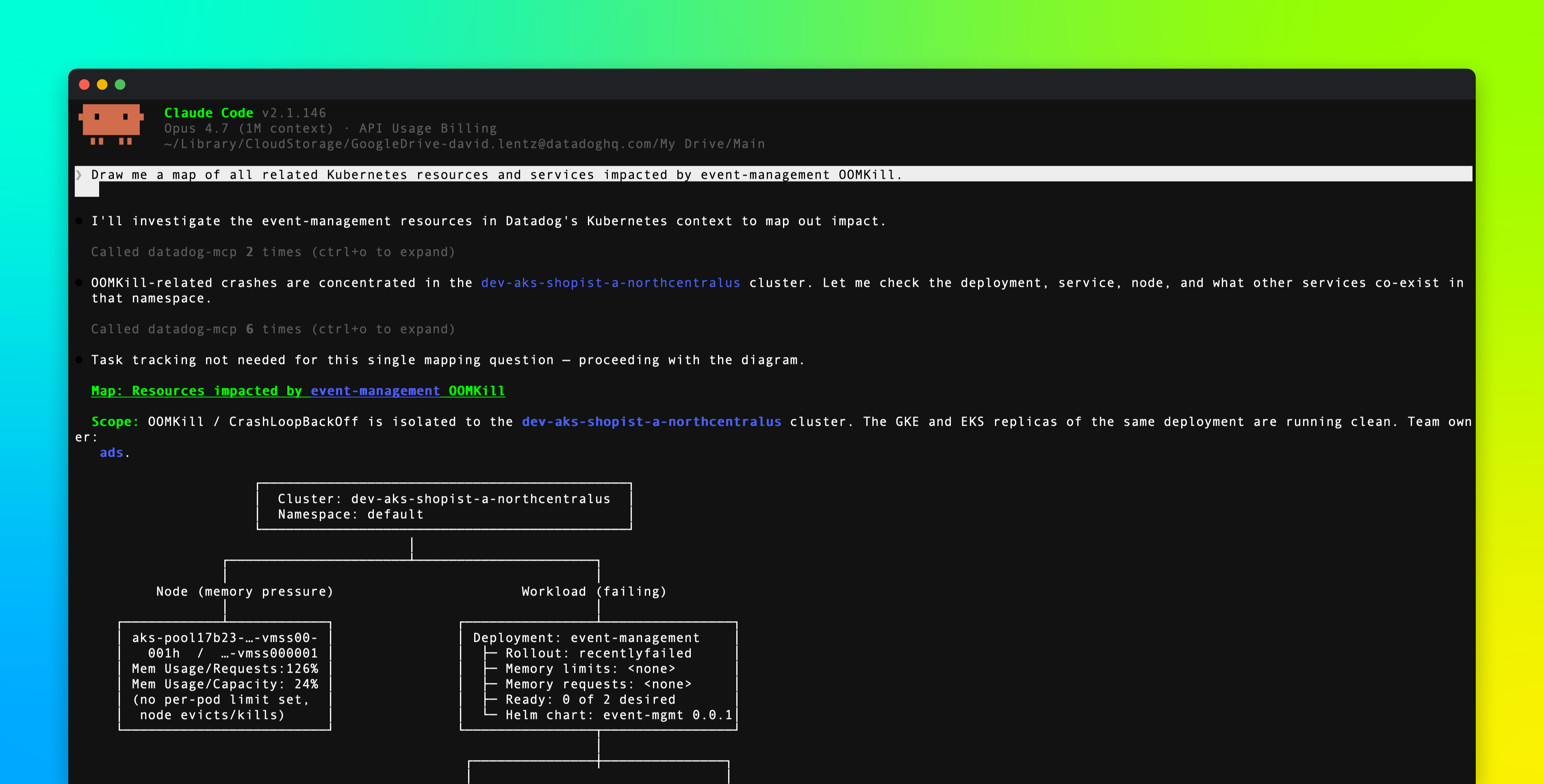
The 2025 State of Containers and Serverless report found that 64% of organizations use the Kubernetes Horizontal Pod Autoscaler (HPA) to manage Kubernetes workload capacity. But only 20% of those deployments scale on custom metrics. The other four-fifths of organizations rely on resource metrics—CPU and memory utilized by their pods—to trigger autoscaling activity.
Resource metrics provide a low-friction way of configuring autoscaling, but they’re not always the most effective scaling signals. Many workloads are constrained by queue backlog, concurrency limits, or tail latency rather than raw CPU consumption. For these services, resource metrics don’t reflect demand accurately enough, and scaling on them can mean scaling too late.
In this post, we’ll identify workload patterns that scale more effectively based on Kubernetes custom metrics instead of resource metrics, and look at how teams currently implement custom metric scaling. We’ll also show you how Datadog Kubernetes Autoscaling (DKA) lets you trigger scaling based on application metrics to help ensure high performance, manage cloud costs, and simplify cluster management.
When standard CPU and memory resource metrics fall short
CPU and memory utilization are lagging indicators of upstream demand, making them an ineffective proxy for the work a service does. Although resource metrics measure consumption in real time, that reflects work that has already entered the system, not the volume of demand as it arrives.