Key Takeaways
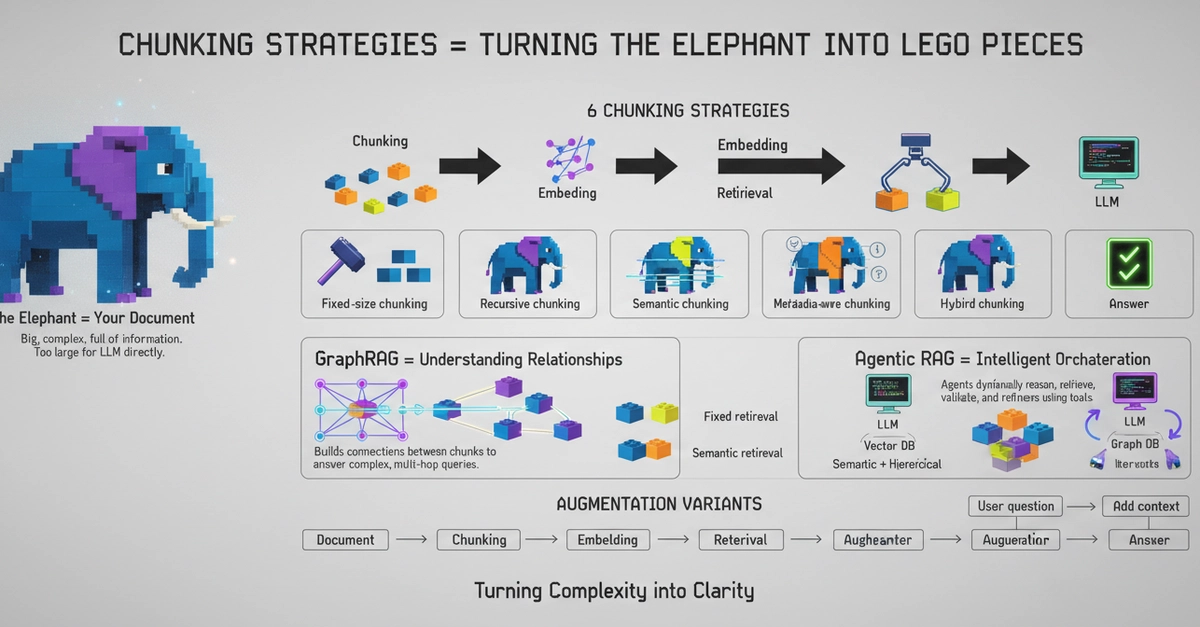
RAG pipeline chunking strategies determine retrieval quality more than the embedding model or vector store — most recall failures trace back to how documents were split during ingestion
Fixed-size chunking (256–512 tokens with 10–15% overlap) is the right starting point for homogeneous prose; semantic and structural strategies outperform it on technical docs and mixed-format corpora
Hierarchical (parent-child) chunking is the highest-performance approach for production systems: small chunks for precise vector retrieval, large parent chunks for full context delivery to the LLM
Always evaluate chunking changes against a golden retrieval set (30–50 annotated queries) before shipping — target recall@3 above 80% before adjusting the embedding model or prompt