Learn how the RAG workflow works — from ingestion and embedding to retrieval, augmentation, and generation. Covers hybrid search, evaluation, and deployment.
by Databricks Staff
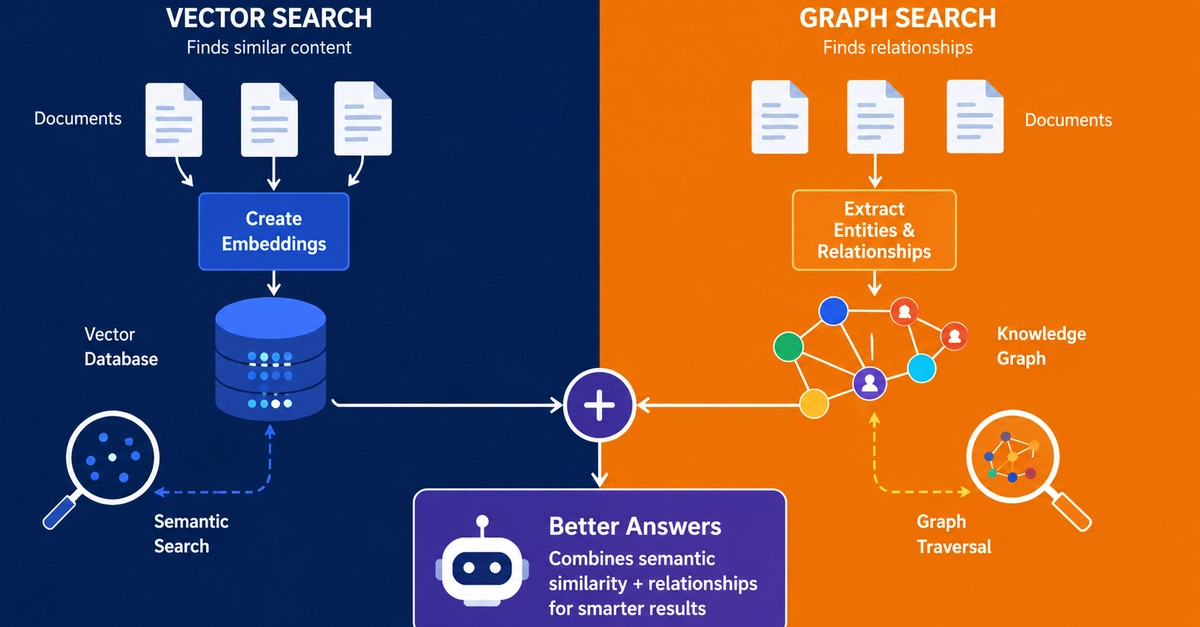
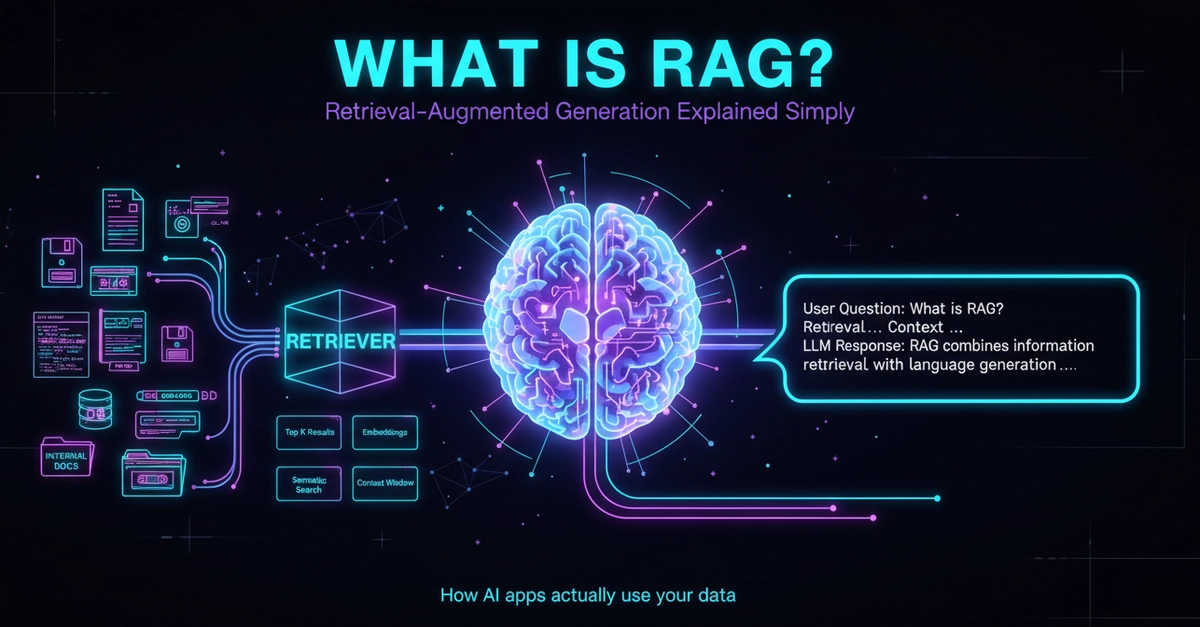
Retrieval Augmented Generation (RAG) is an AI architecture pattern that connects large language models to external knowledge sources at inference time, enabling those models to generate accurate, context-aware responses that go beyond their static training data. Rather than relying on knowledge encoded during pretraining, a RAG system retrieves relevant documents from an external database in response to each user query and injects that content into the LLM prompt before generation. The result is a generative AI system that produces accurate, domain-specific answers grounded in verified sources — without requiring full model retraining every time the underlying knowledge changes.
LLMs often provide outdated answers due to knowledge cutoffs and cannot access proprietary internal documents or real-time external data sources. RAG directly addresses this limitation. Over 60% of organizations are actively developing AI-powered retrieval tools, reflecting a fundamental shift from relying solely on model memory to dynamically connecting AI to live knowledge bases containing internal documents, product documentation, and current data.