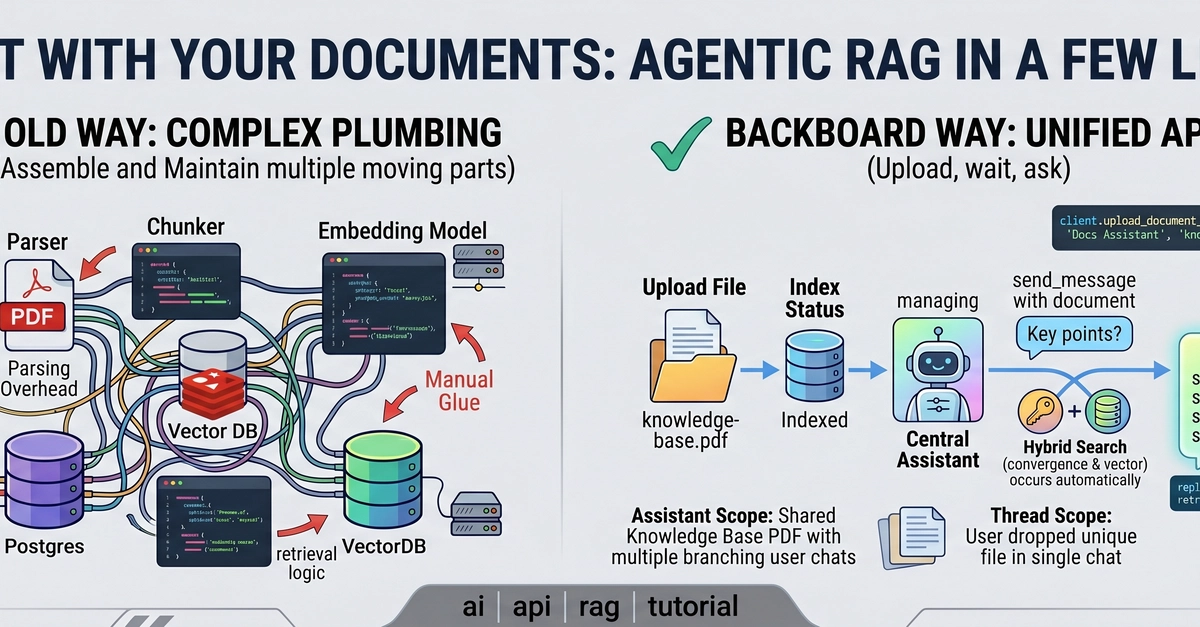
Retrieval-Augmented Generation (RAG) is a practical pattern: store knowledge as embeddings, retrieve the most relevant chunks with semantic search, then generate an answer grounded in that context.
This guide shows a simple end-to-end flow with OpenAI embeddings, PostgreSQL + pgvector, and LangChain chunking.
Prerequisites
OpenAI account
Generated API key