Retrieval-augmented generation (RAG) connects LLM answers to your own documents instead of relying on training data. This tutorial builds a complete pipeline with Runware handling generation on purpose-built inference infrastructure, which is faster and cheaper than commodity providers, through an OpenAI-compatible endpoint, and LangChain handling the indexing and retrieval layer.
Without retrieval, assistants either hallucinate details such as inventing API fields or policies that don't exist or go stale the moment your docs change. RAG fixes both by pulling the relevant passages before generation.
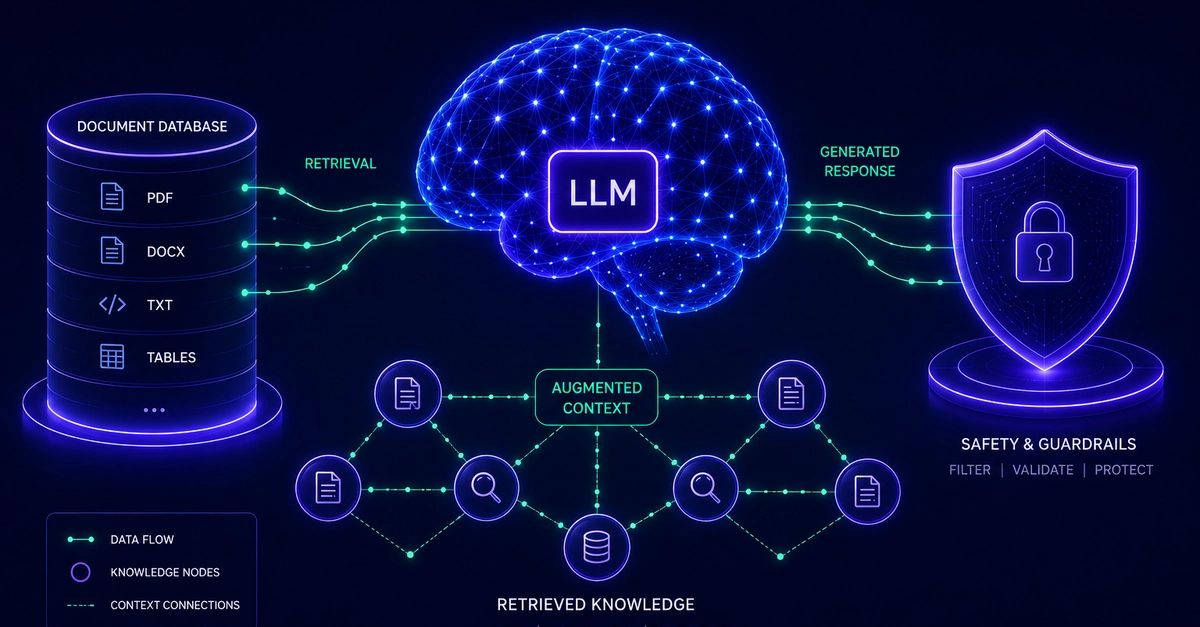
The RAG pattern
RAG retrieves relevant document chunks at query time and adds them to the prompt so the model answers using that specific context. Unlike memory, which tracks user info across sessions, RAG surfaces up-to-date docs (like APIs or policies). Mixing user chat logs into RAG often leads to stale or sensitive results, so use each for their purpose.
As you scale, remember these tips: