Retrieval-augmented generation looks trivial in a tutorial: embed some documents, drop them in a vector database, stuff the top matches into a prompt, done. Then you point it at real company data and real users, and you discover that the demo was the easy 10%.
We build RAG systems over private knowledge for companies, and almost every painful bug traces back to the same handful of failure modes. Here they are, and what actually fixes them.
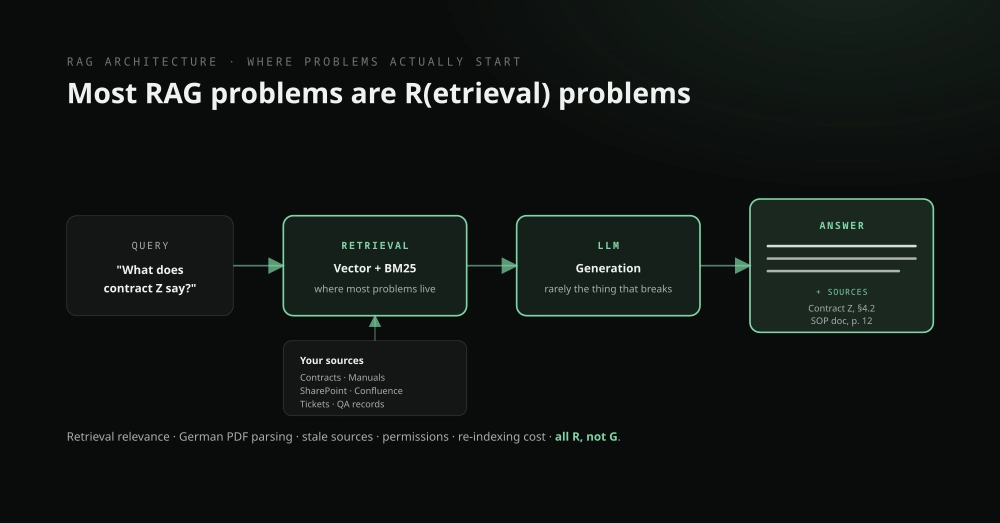
1. Retrieval returns the wrong chunks — and the model uses them anyway
The single biggest source of "wrong" RAG answers isn't the LLM. It's retrieval handing it irrelevant or partial context, which the model then summarizes with total confidence. Naive fixed-size chunking splits a table from its header, or a clause from the sentence that negates it.
The fix is unglamorous data engineering: chunk on semantic boundaries, not character counts; add a reranking step so the top-k you actually pass is the top-k by relevance, not by raw vector distance; and store enough metadata to filter before you search. Retrieval quality sets the ceiling on everything downstream.