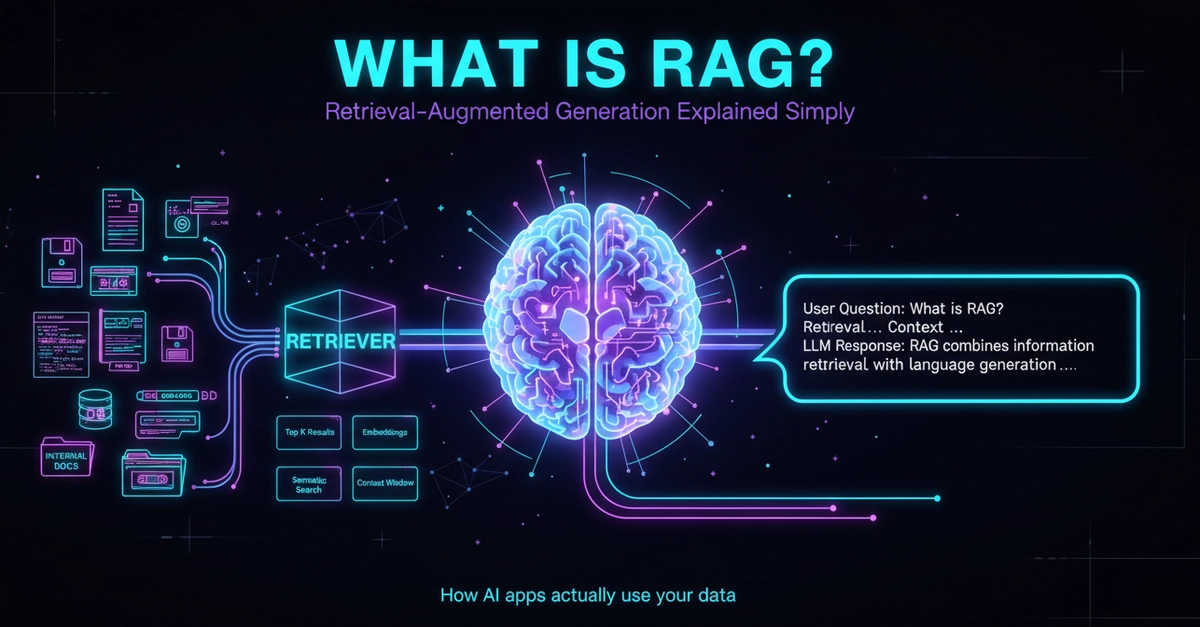
It started innocently enough. I needed a way to let my team ask questions about our sprawling internal documentation—hundreds of pages of API references, onboarding guides, and compliance rules. ChatGPT was impressive, but it had no clue about our private data. The obvious answer: Retrieval-Augmented Generation (RAG).
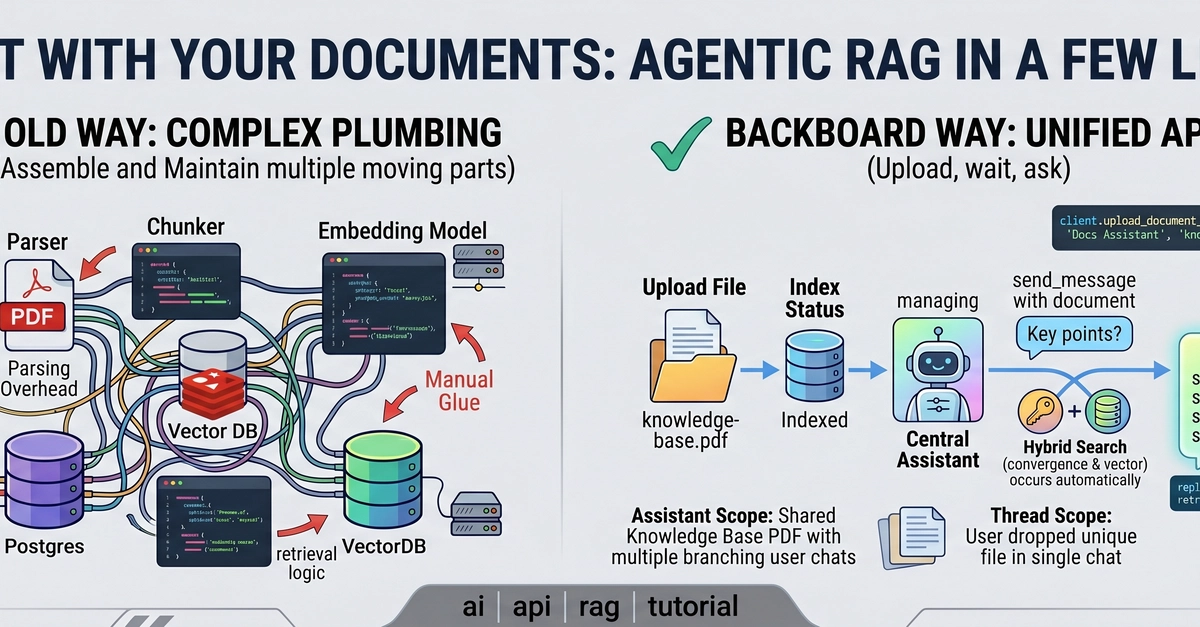
I’ve read the hype: embed your docs, shove them into a vector database, slap an LLM on top, and boom—instant Q&A bot. Sounds simple. My first attempt was anything but.
The naive approach that almost worked
I grabbed text-embedding-ada-002, split my documents into 512-token chunks, inserted them into Pinecone, and wired up a simple LangChain chain with GPT-3.5-turbo. Here’s the monster I created:
from langchain.embeddings.openai import OpenAIEmbeddings