RAG Retrieval Gotchas at Scale: Insights and Solutions
Retrieval-Augmented Generation (RAG) has become a popular technique for enhancing natural language processing (NLP) models by combining the generative capabilities of models like BERT and GPT with a retrieval mechanism. This approach is particularly useful for applications that require access to large datasets, such as question-answering systems, chatbots, and more. However, implementing RAG at scale comes with its own set of challenges. In this article, we will explore common gotchas and provide concrete solutions based on real-world scenarios.
1. Understanding the RAG Architecture
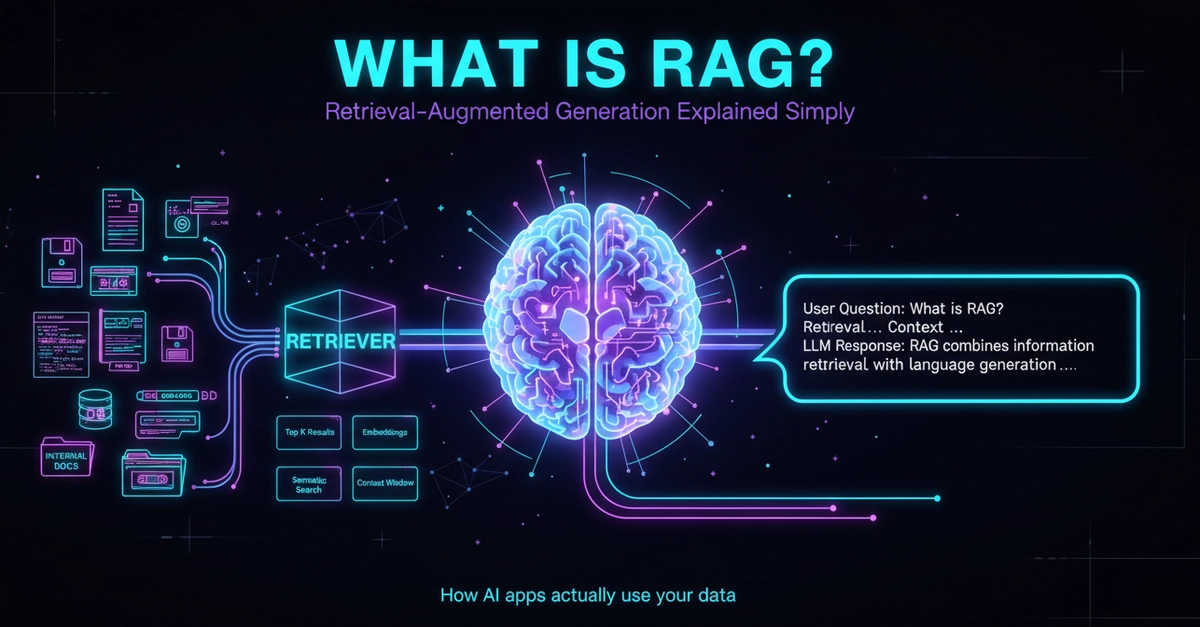
Before diving into the specifics, let’s briefly cover the architecture of a RAG system. RAG typically consists of two main components:
Retriever: This component fetches relevant documents based on a given query. It can be implemented using various algorithms, but dense retrieval methods using embeddings are common.