Learn how chunking impacts retrieval quality, embedding performance, and the overall effectiveness of Retrieval-Augmented Generation (RAG) systems.
Introduction
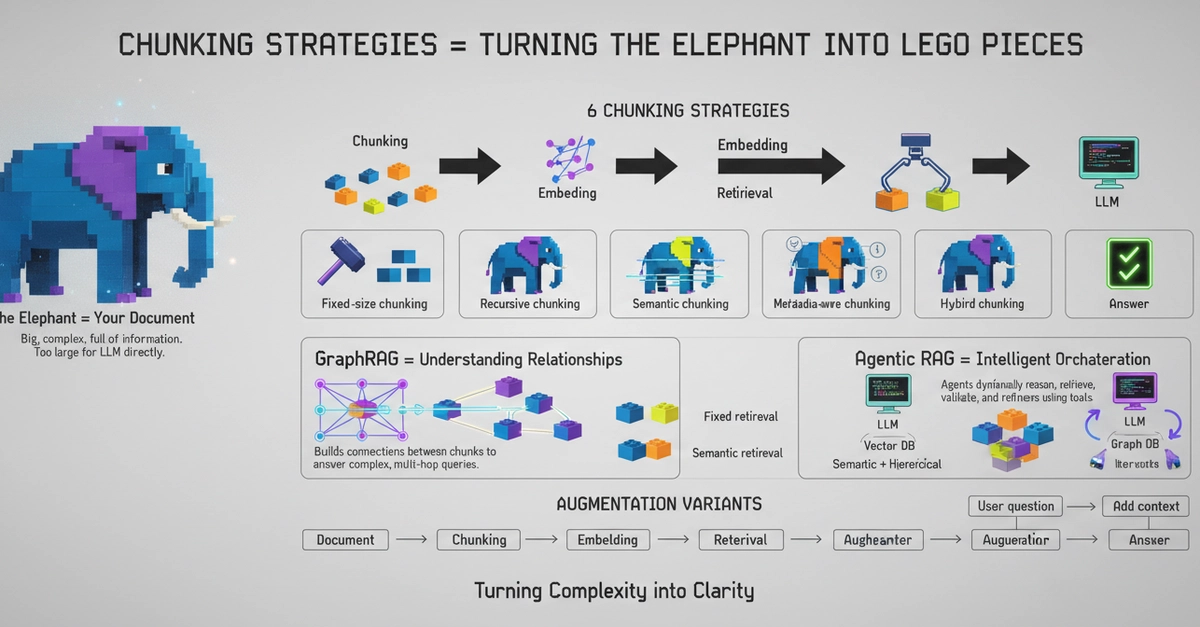
When building AI applications using Retrieval-Augmented Generation (RAG), developers often focus on selecting the best LLM or embedding model. But one foundational step is frequently underestimated chunking
Chunking
Chunking is the process of breaking large documents into smaller, manageable pieces before generating embeddings and storing them in a vector database.