Introduction
Here is a scenario many RAG builders know well, you wire up a pipeline, load your documents, ask a question and the answer is wrong, vague, or confidently hallucinated. The information was right there in your knowledge base. So what went wrong?
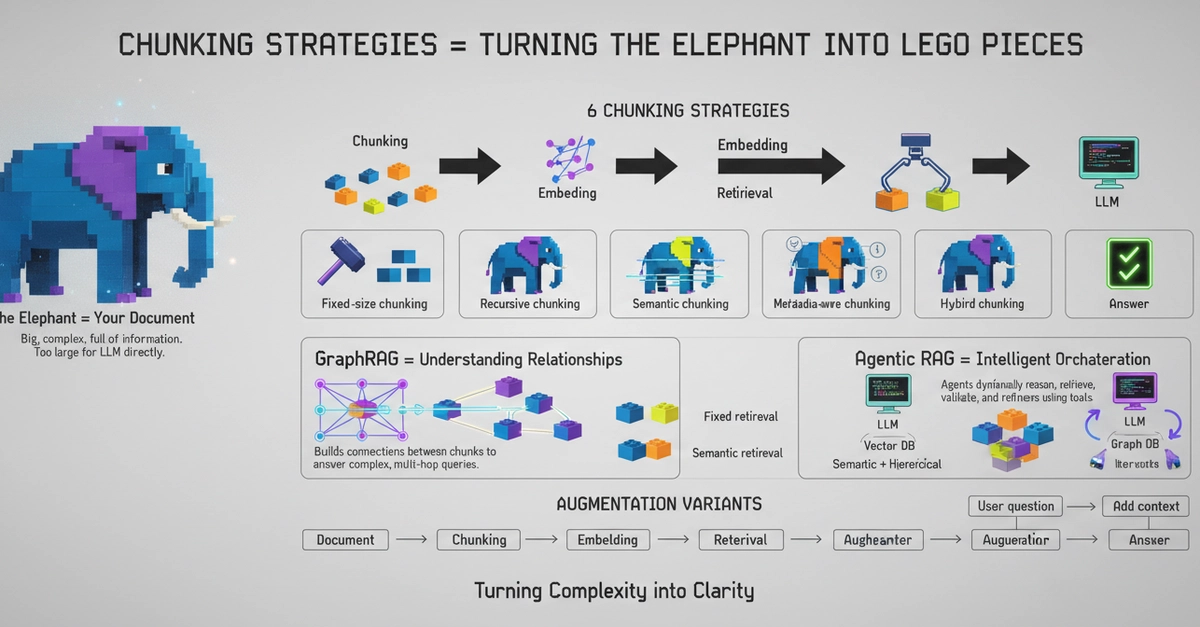
In most cases the problem is not your embedding model. It is not your LLM. It is how you cut up your documents before storing them the under appreciated craft called chunking and whether the retrieval architecture you chose actually matches the complexity of your queries.
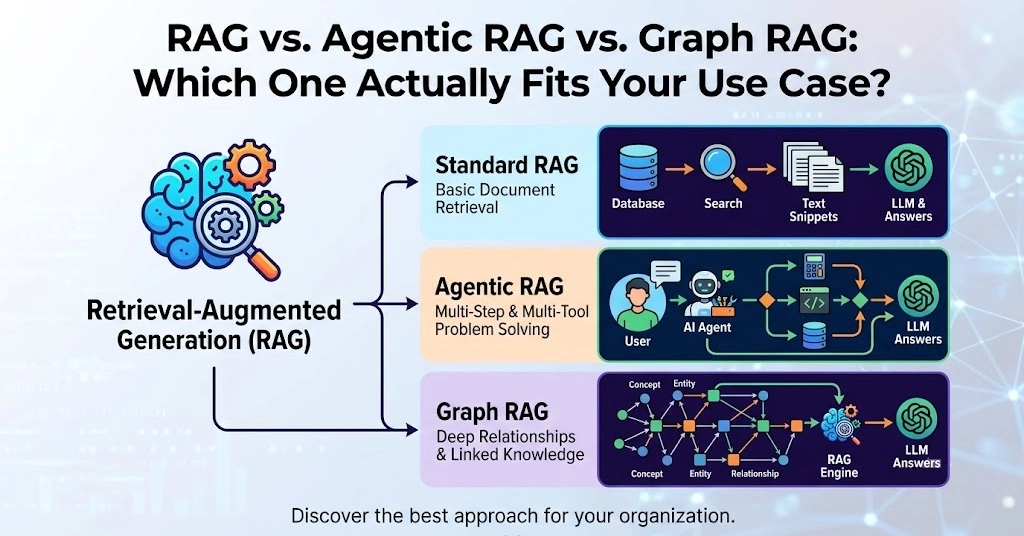
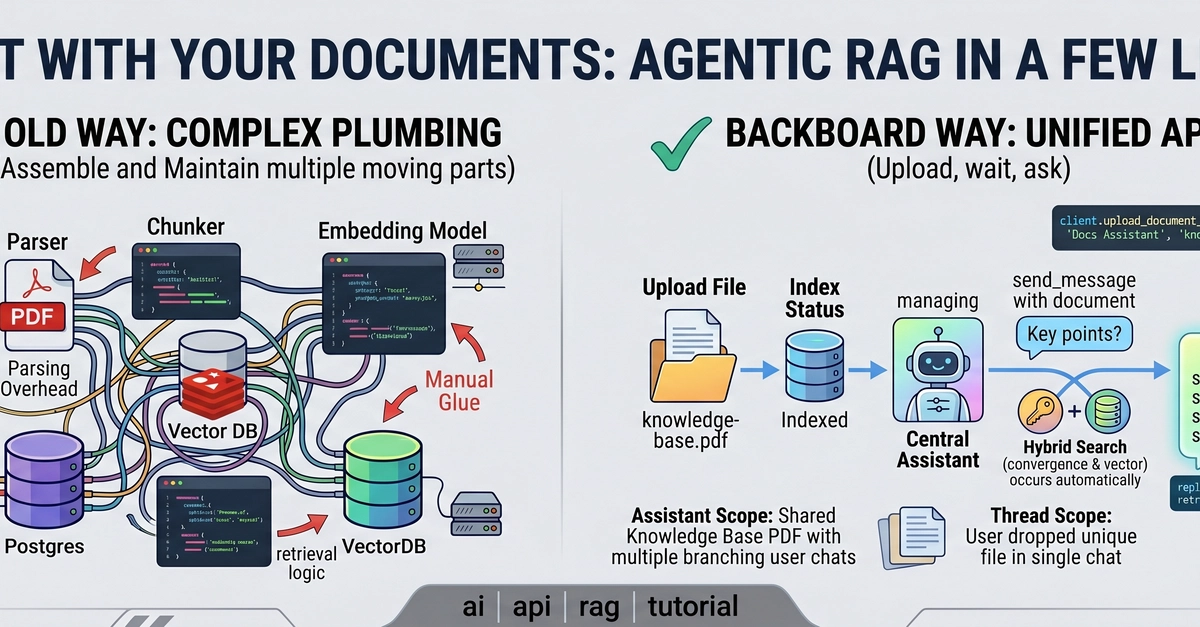
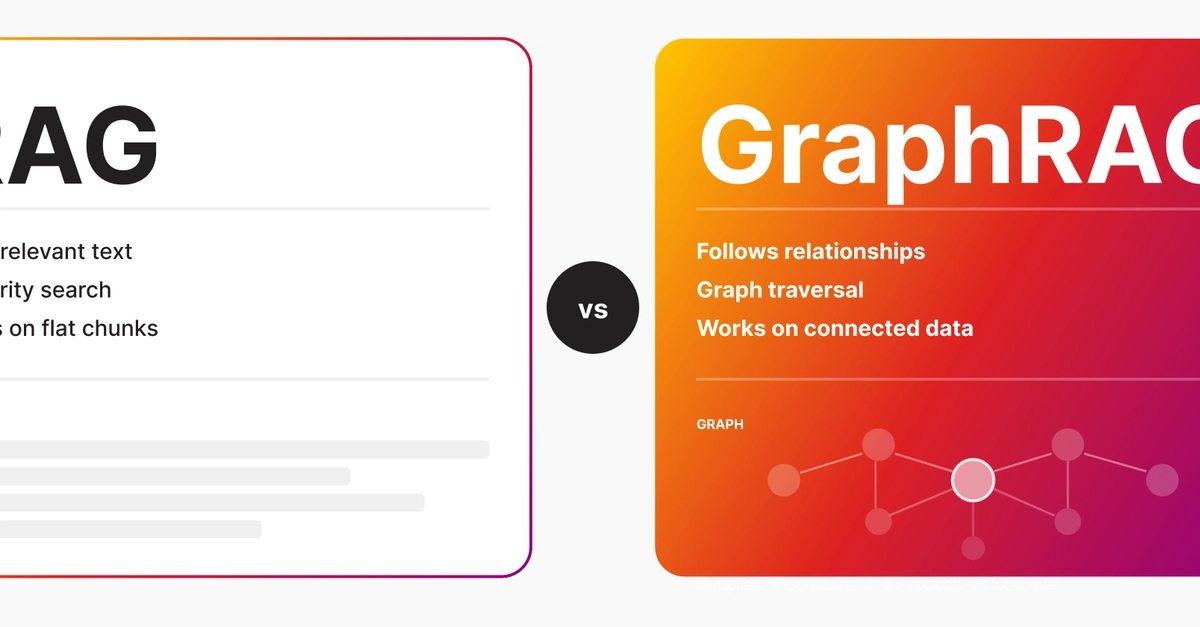
This blog walks you through every major chunking strategy, explains how retrieval and augmentation work on top of those chunks, covers two advanced architectures Agentic RAG and GraphRAG and most importantly gives you a complete decision framework so you can walk away knowing exactly which combination fits your use case.
Your document is an elephant.