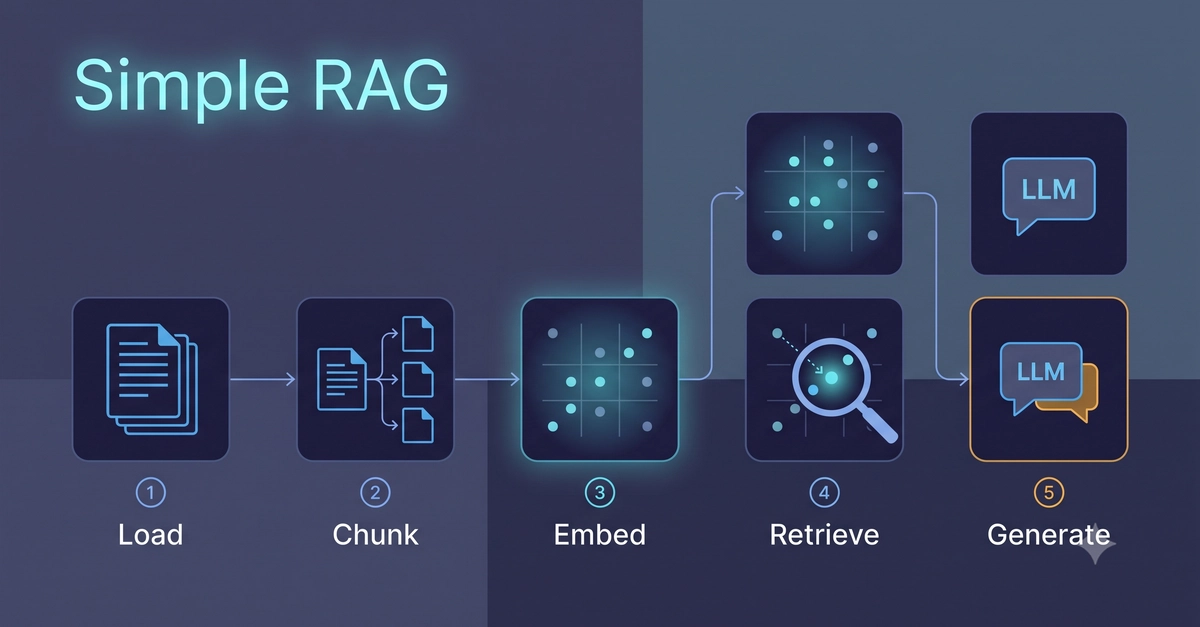
Most RAG tutorials stop at "embed your docs, do a similarity search, stuff the results in a prompt." That gets you a demo. It does not get you something that gives correct, grounded answers on real data — and the gap between those two is where all the actual engineering lives.
A RAG pipeline is a series of stages, and a weak link in any one of them caps the quality of the whole thing. You can have a frontier model and a beautiful prompt, and still ship garbage if your chunking is wrong. So this is the pipeline end to end, with the production patterns that decide whether it works — not just the happy-path demo.
If you're still deciding whether RAG is even the right tool versus fine-tuning, read RAG vs Fine-Tuning for LLMs first. This post assumes you've decided to retrieve.
TL;DR
RAG is a pipeline: ingest → chunk → embed → store → retrieve → generate. The output is only as good as the weakest stage.