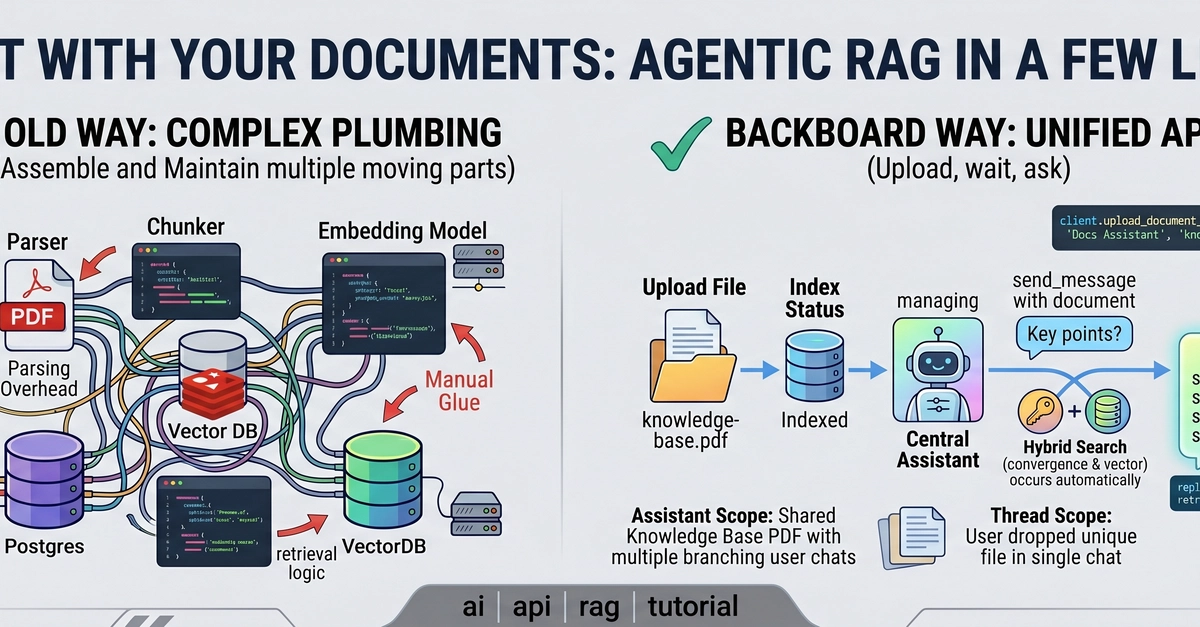
Chunking sounds like the boring part of RAG. It is also where a lot of retrieval quality is won or lost. I built a document chunking and embedding API and ran it in production, and these are the things that actually moved the needle.
Repo: https://github.com/ahmetguness/doc-chunking-api
Live demo (3 free runs): https://chunkingservice.com
Sentence-aware beats fixed-size
The naive approach is to split text every N characters or tokens. It is simple and it quietly hurts retrieval, because it cuts sentences in half and splits ideas across chunks. Sentence-aware chunking with a configurable overlap keeps each chunk coherent, so the embedding actually represents a complete thought. This one change usually improves retrieval more than swapping embedding models.