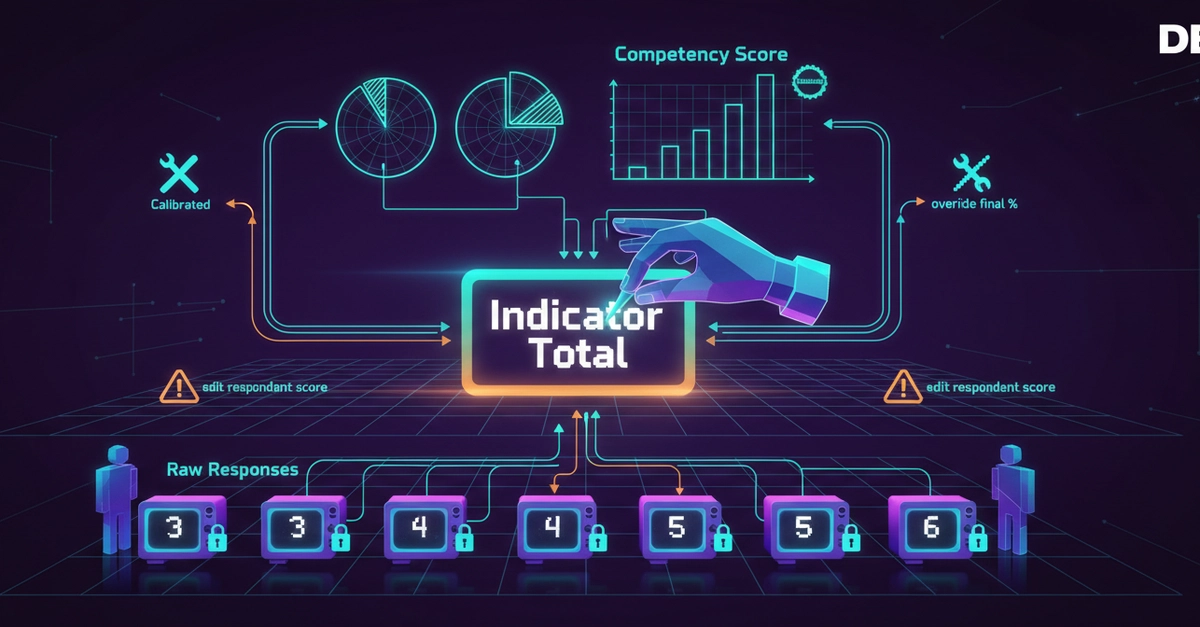
A 360 review collects answers from three to ten people about one person. Then the reviewer sits down to "calibrate" the result. The industry default is one of two paths: rewrite individual respondent scores, or override the per-competence percent at the very end. We tried both. Neither aged well. This week we shipped a third option, and we're not done thinking about it.
This post is half a release note, half an open question.
The raw-score calibration trap
The natural place to put calibration is on the raw answer. Respondent A gave 3, B gave 5. The reviewer thinks the real answer is 4, so they edit one of those numbers and recompute.
Two problems with that.






