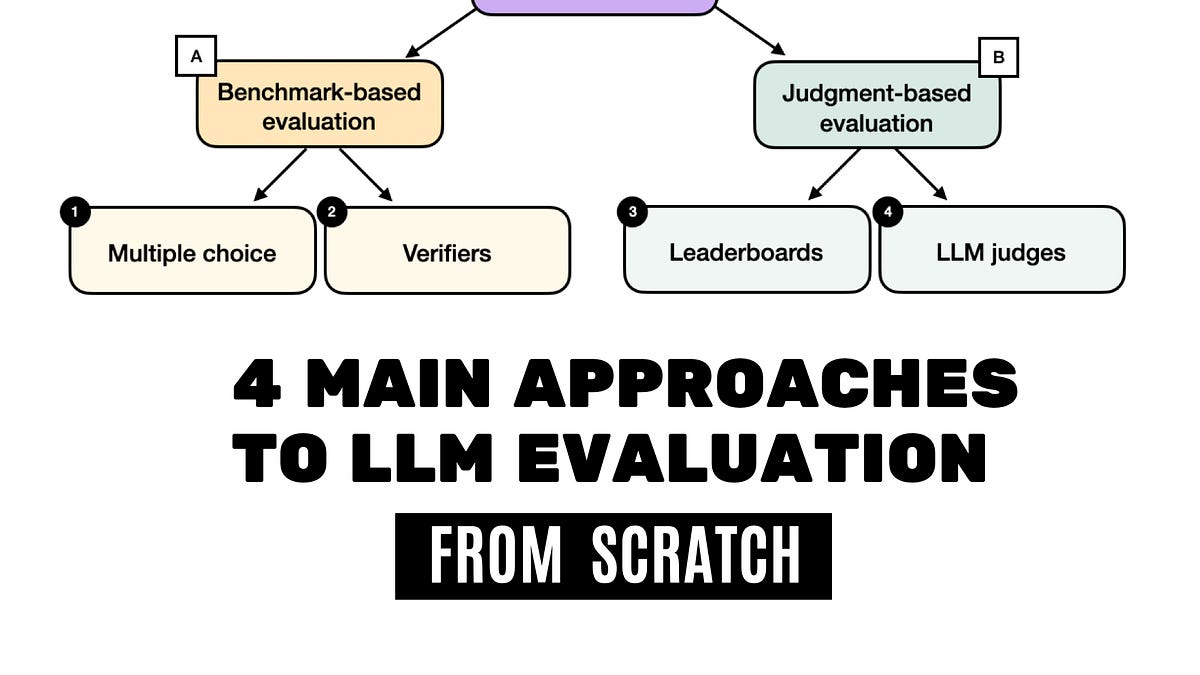
The standard workflow for evaluating LLM output quality goes something like this: someone reads Response A, reads Response B, and says "I think A is better." Everyone nods. The prompt ships.
This is a problem for three reasons:
It doesn't scale. You can't manually review 500 eval pairs after every prompt change.
It's inconsistent. The same person evaluating the same pair on different days produces different results.
It doesn't tell you why. "Response A is better" doesn't tell you what to fix when Response B becomes the baseline.