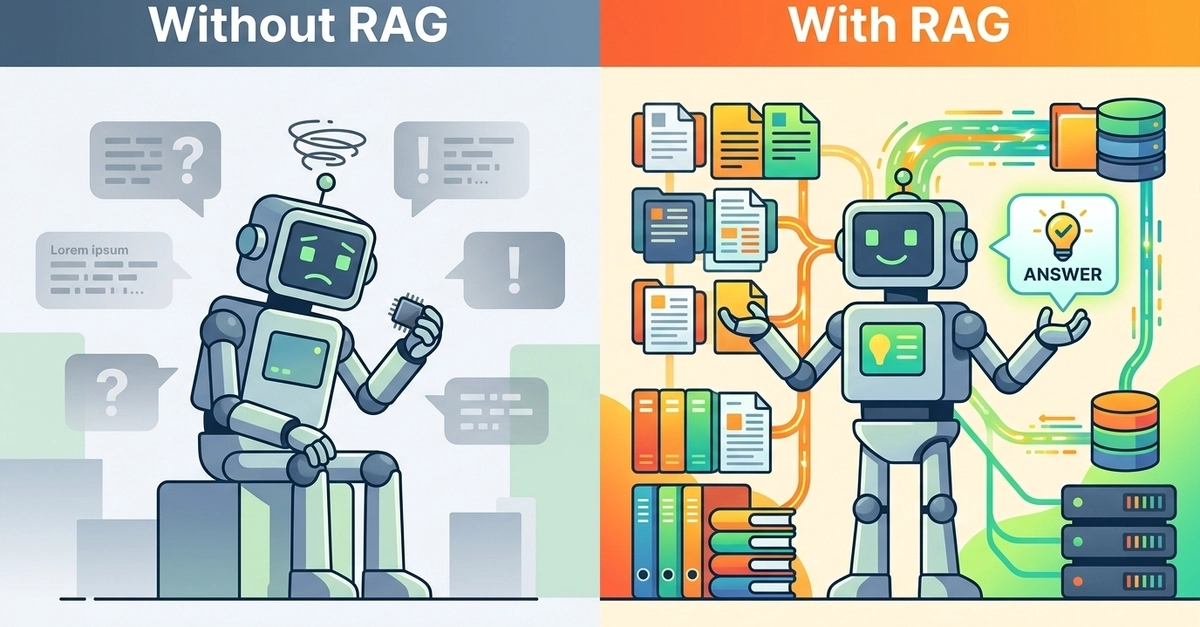
In my research on hallucination detection in multi-agent LLM systems, the most consistent findings have not been about model size, prompt design, or inference temperature. It has been about retrieval. Poor retrieval quality is the single most reliable predictor of degraded output across every pipeline configuration I have studied.
The evidence from our experimental pipelines is unambiguous: when retrieval breaks down, the language model does not compensate. It extrapolates. It fills gaps with plausible-sounding content that has no grounding in fact, and it does so with the same fluency and confidence as it applies to correct outputs. The result is a failure mode that is both systematic and exceptionally difficult to detect without a dedicated evaluation infrastructure.
This post draws on that research to offer a structured, practitioner-facing analysis of retrieval quality: what it is, why it matters more than most teams realize, how it fails in practice, and what can be done to improve it. Whether you are building a production RAG pipeline or designing a multi-agent system, the principles here apply directly to the reliability of what your LLM ultimately produces.
Understanding the Retrieval Layer in RAG Systems