If you’re building visual shopping, image or document understanding, or chart analysis, you need a way to verify whether your model’s response is actually grounded in the source image. A text-only evaluator cannot tell you whether a caption faithfully describes an image, whether an extracted invoice total matches the document, or whether a screen summary hallucinated a button that was never on the page. Gartner predicts that by 2030, 80% of enterprise software will be multimodal, up from less than 10% in 2024. Without automated multimodal evaluation, you’re stuck between expensive human review and unreliable text-only proxies.
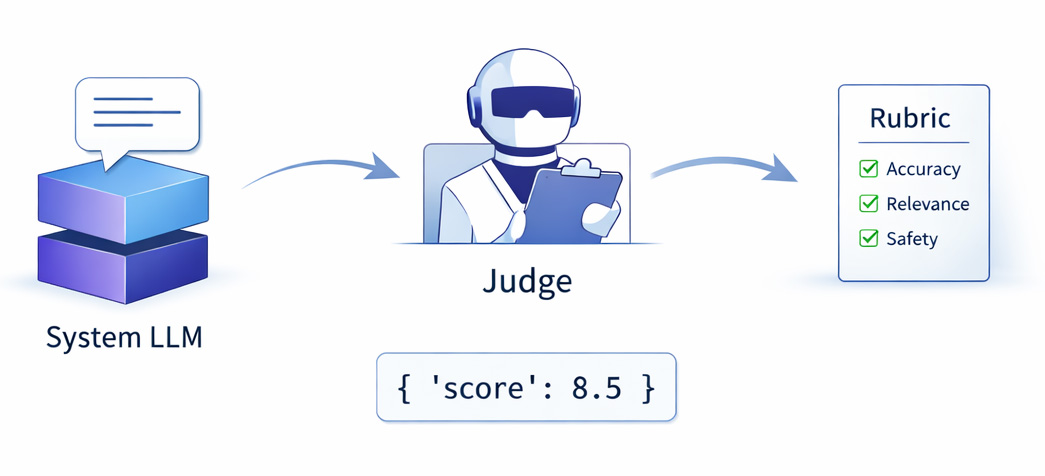
Today, we’re announcing four new multimodal large language model (MLLM)-as-a-Judge evaluators for image-to-text tasks in Strands Evals software development kit (SDK): Overall Quality, Correctness, Faithfulness, and Instruction Following. Each evaluator scores image-to-text outputs against the source image. The evaluator sends the image directly to a multimodal judge model, alongside the query, the response, and (optionally) a reference answer. The judge returns a score grounded in the image, together with a reasoning string you can use for debugging. You can use these evaluators as drop-in replacements for text-only judges in your existing Strands Evals Case → Experiment → Report workflow, and plug them into continuous integration (CI) to catch visual hallucinations, factual errors, and instruction violations automatically.