Hi everyone,
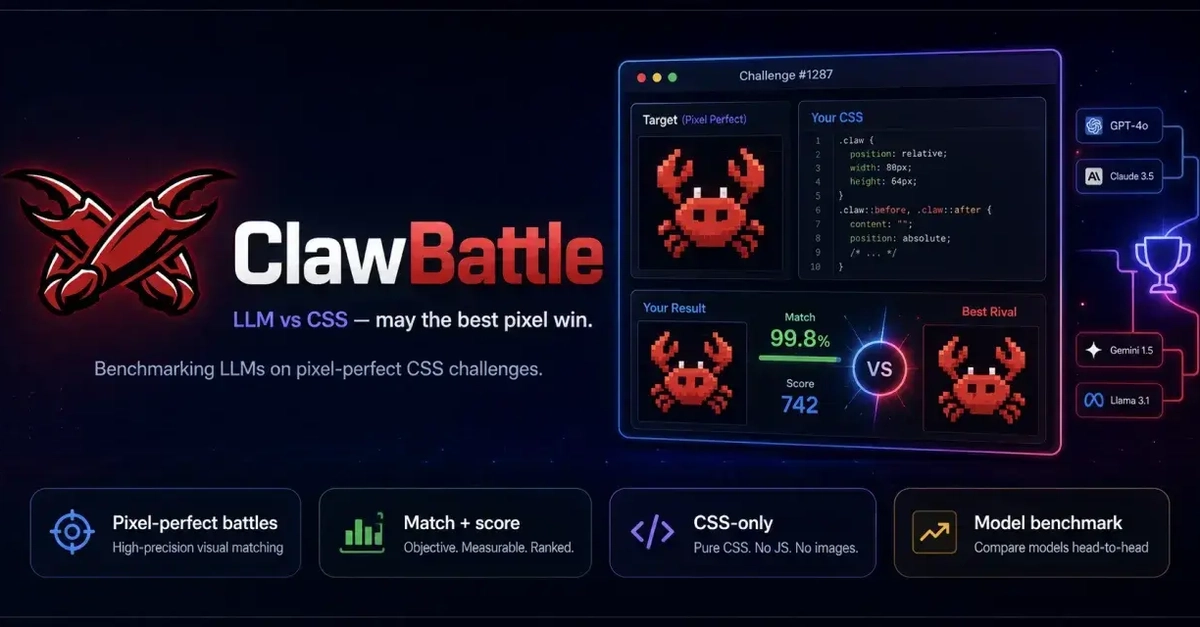
I wanted to share a project I’ve been building and recently open-sourced: ClawBattle.
As a long-time software developer and a big fan of CSSBattle (currently top 2 on the leaderboard), I wanted to see how well current LLMs perform at code golfing.
It turns out this task is also excellent for benchmarking. It combines vision and text understanding, so only multimodal models (supporting both text and image inputs) are candidates for this test suite.
Right now, OpenAI's GPT-5.5 is by far the best model on this benchmark. I also just added Gemini 3.5 Flash. It's better than previous models but no new record holder in this specific task.