Back to Articles
Evaluation is broken What We're Shipping Why This Matters Get Started
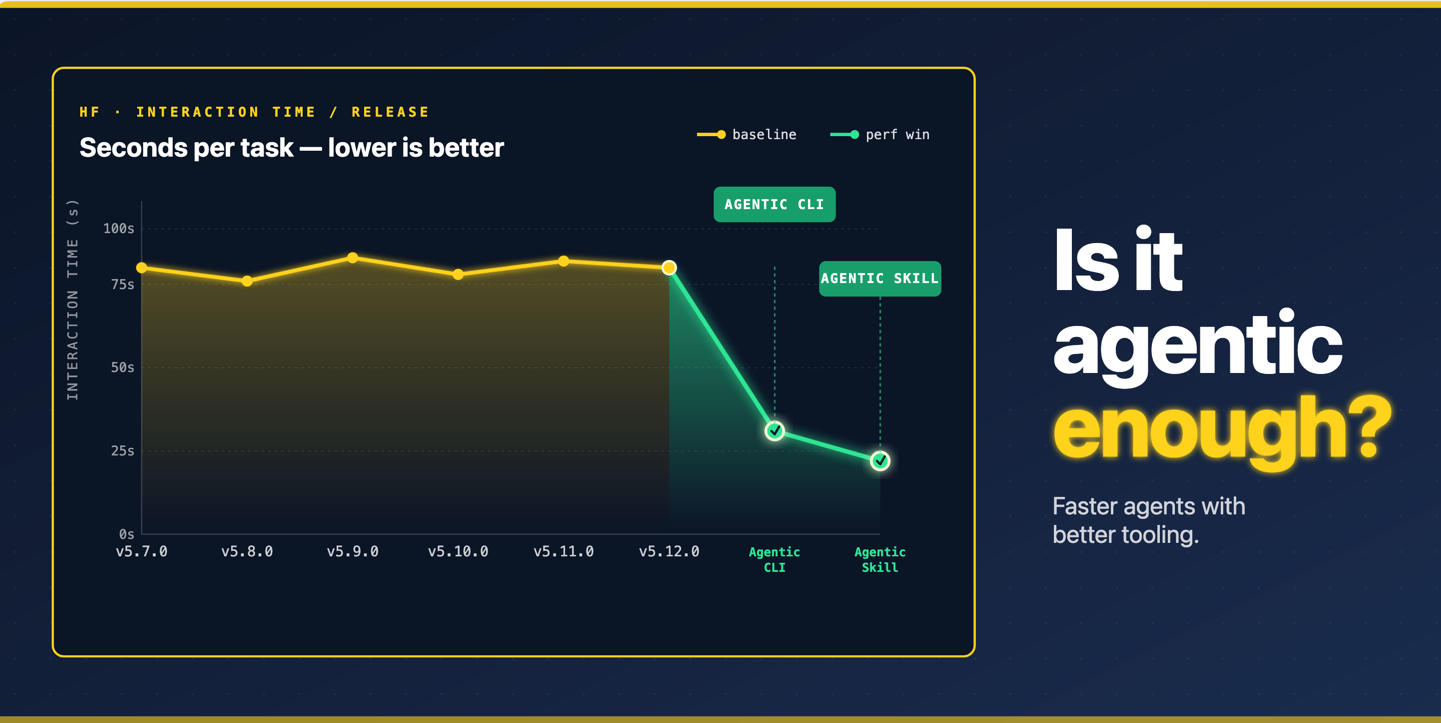
TL;DR: Benchmark datasets on Hugging Face can now host leaderboards. Models store their own eval scores. Everything links together. The community can submit results via PR. Verified badges prove that the results can be reproduced.
Evaluation is broken
Let's be real about where we are with evals in 2026. MMLU is saturated above 91%. GSM8K hit 94%+. HumanEval is conquered. Yet some models that ace benchmarks still can't reliably browse the web, write production code, or handle multi-step tasks without hallucinating, based on usage reports. There is a clear gap between benchmark scores and real-world performance.