Back to Articles
Testing software for agentic-use Not all successes are equal How do we run evaluations? Which models to benchmark against? Large open models: hold the model, vary the revision Small models: hold the revision, vary the model Tweaking the tool: markers and results What's a marker? Is the CLI + Skill commit helping? Trying it yourself Closing Acknowledgements
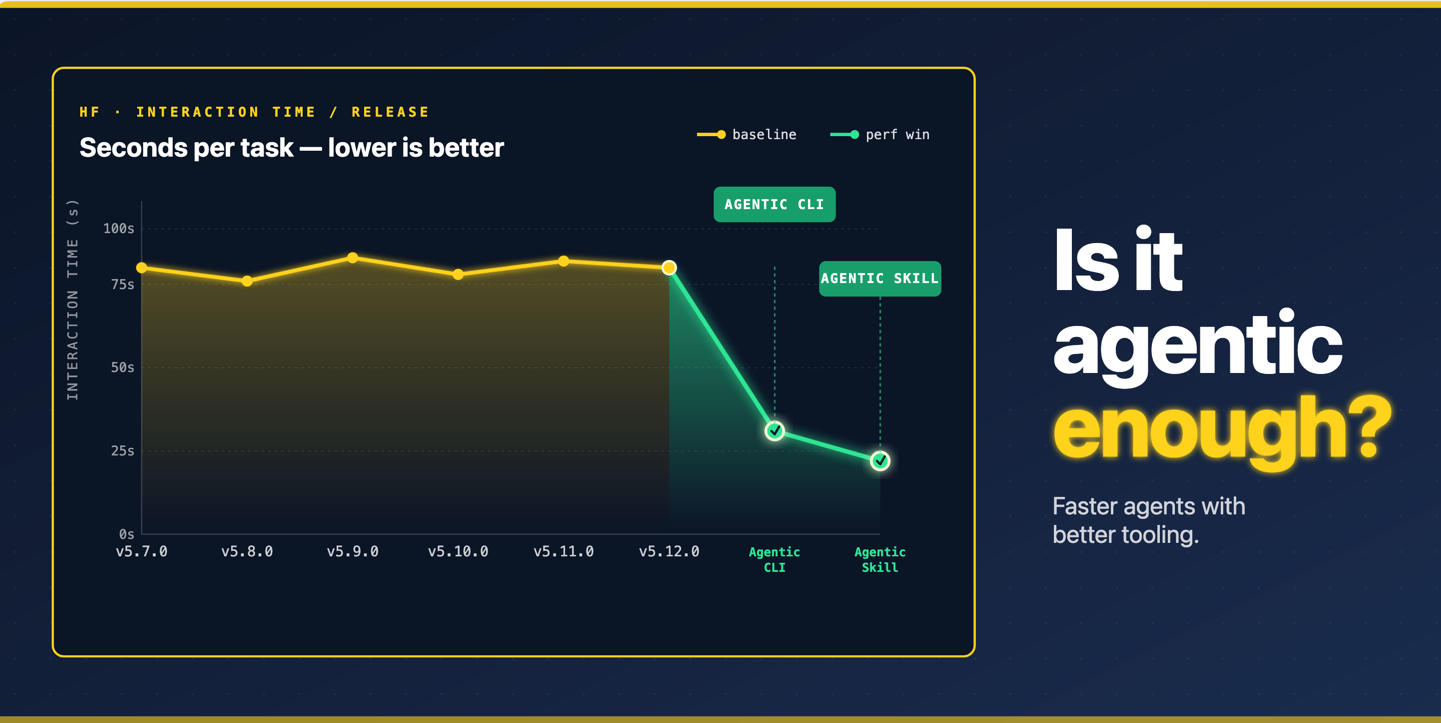
Benchmarking transformers revisions across different metrics
This is a human-made, agent-focused blogpost.
Coding agents increasingly work with our software instead of us: describe a task, and the agent picks the library,