Claude Opus 4.7 shipped last week, and the question any engineering team reaches for is how it compares to its peers.
It is the strongest frontier coding model we tested on the baseline leaderboard, and it will be the easy default a lot of teams reach for.
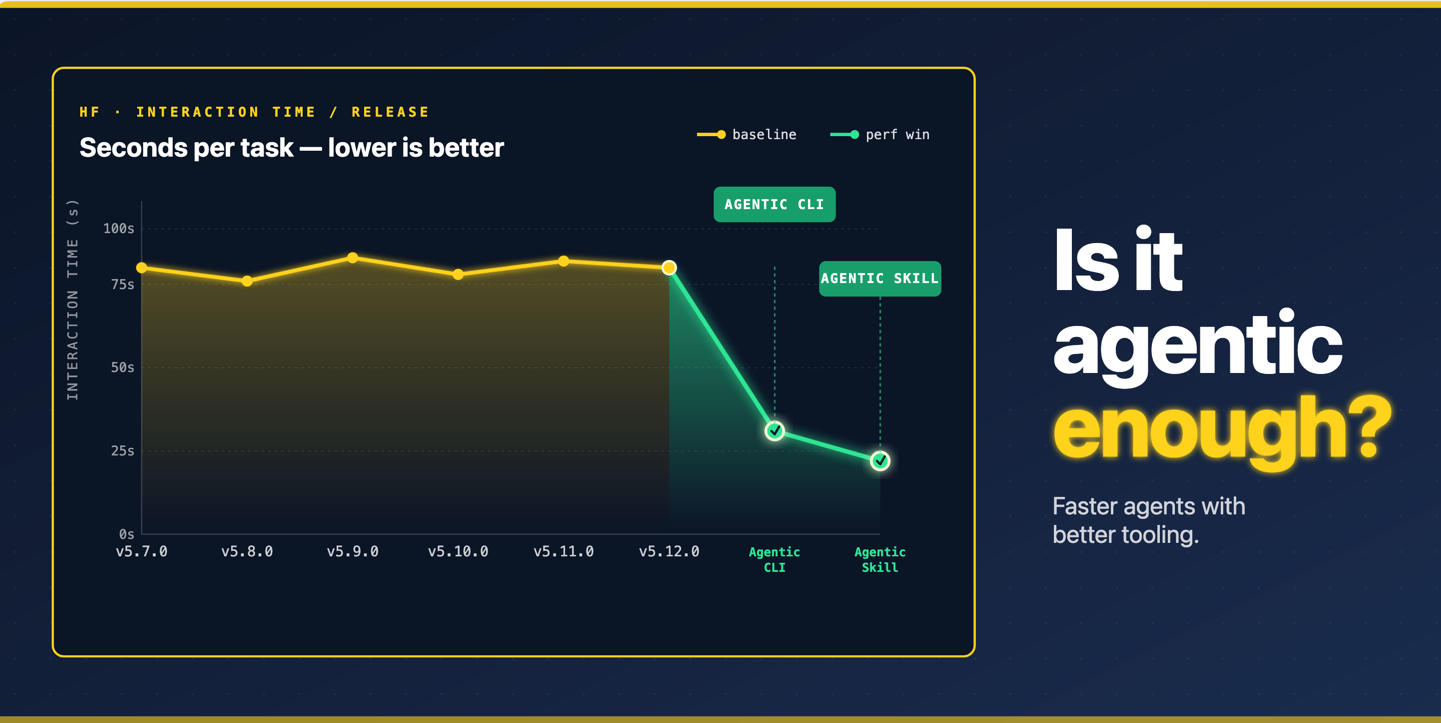
But in 2026, the model you reach for could matter less than the skill you load with it.
That is what 880 evals across nine models (Opus 4.7, Opus 4.6, Sonnet 4.6, Haiku 4.5, gpt-5.4, gpt-5.3-codex, gpt-5-codex, and Cursor's Composer-2) tell us.
Let’s take a step back. It’s now 2026, and agent skills are spreading like wildfire… (even our favourite movies are catching up to them).