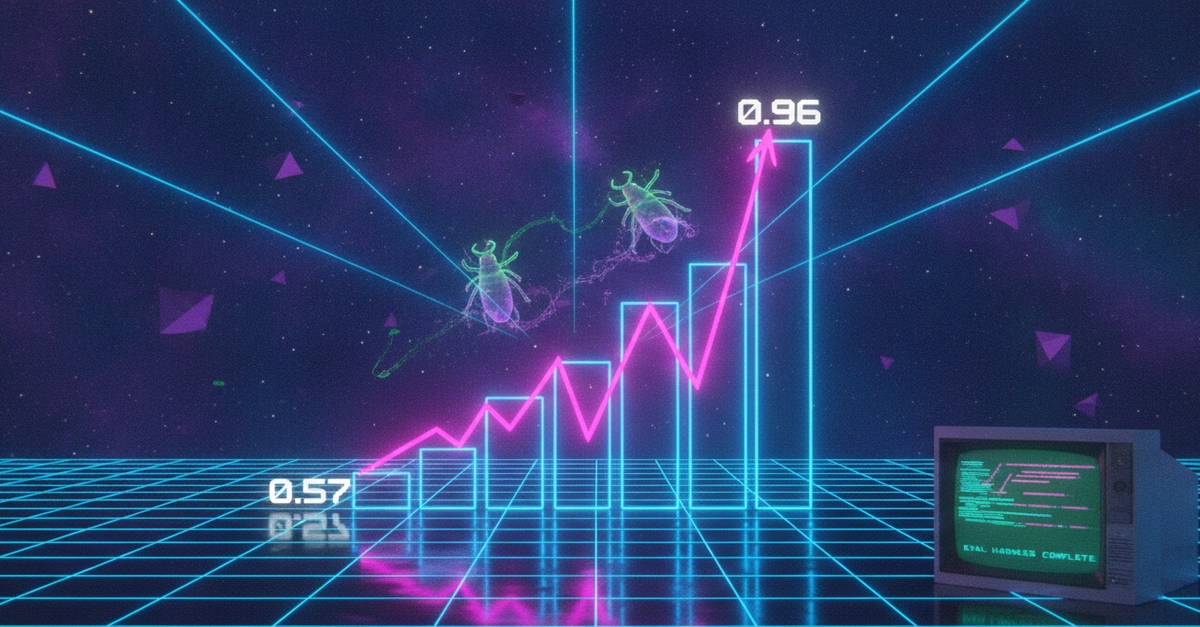
TL;DR: We replaced our "did the agent finish the task" pass/fail eval with a token-level harness that scores tool selection, argument shape, and recovery behavior separately. Pass rate went from a single 73% number to four signals that actually tell us what broke. Bifrost sits in front as the provider switch so the same eval runs against four models without rewriting the harness.
At Nexus Labs we run agent automation for enterprise workflows. Twelve people on the team, around 40 tool definitions across the production agents, mix of GPT-4.1, Claude Sonnet 4.6, and a fine-tuned Qwen3 32B we serve ourselves on vLLM.
Last quarter our eval suite told us the new agent build was "72% passing." Shipped it. Two customers reported the agent was silently picking the wrong tool and confabulating success. Pass rate didn't catch it because the final assistant message looked fine.
So we rebuilt the harness.
The four signals