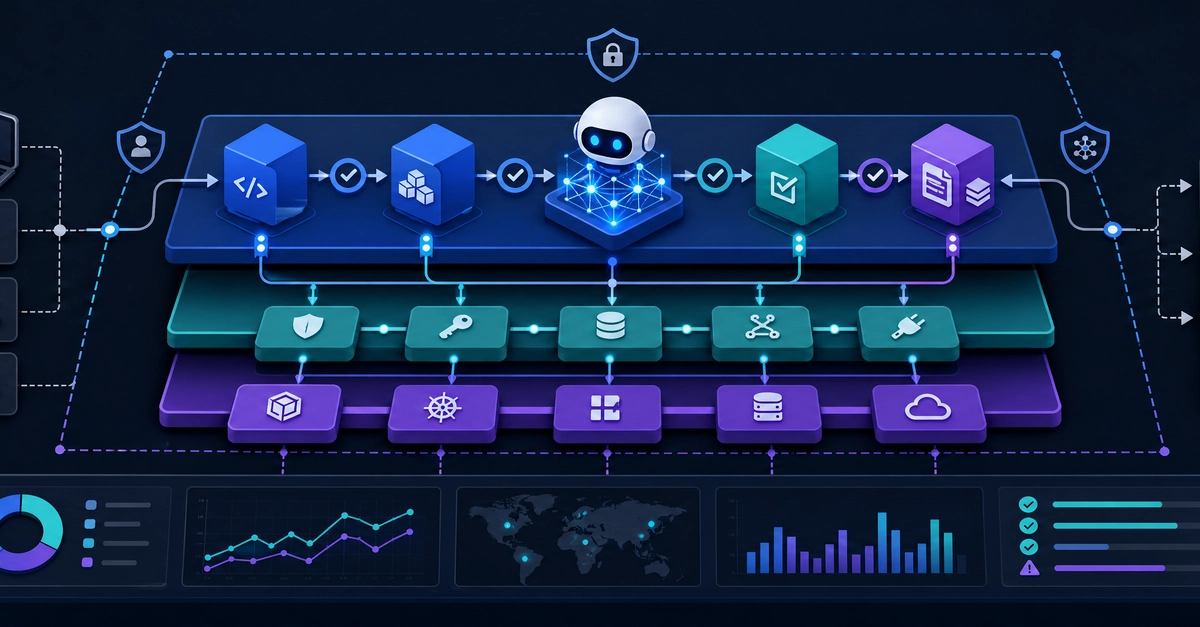
tl;dr — Agents are good at small fixes and terrible at "make this algorithm better" because every change looks good in isolation and silently regresses elsewhere. We built an AI harness — immutable test set, multi-axis rubric, sweep tool, independent reviewer agent, human-viewable eval interface, knowledge-persistence layer — that lets an agent iterate on a real algorithm autonomously while a human still contributes intuition at the right layer. Twenty-five shipped versions of our color quantization pipeline in 13 days (git log doesn't lie); the most recent six of them in five days, right after the harness itself got an upgrade. The harness, not the prompts or full automation, is what made that pace safe.
Two important caveats up front, because they change how the rest of this article reads:
This is spare-time work on a side project — evenings, weekends, the occasional lunch break. Not a full-time team, not a dedicated sprint.
The author is a product manager who cannot read a single line of code. Every line of the actual quantization pipeline was written by AI agents. The author's contribution is the harness, the hypotheses, and the human-eye review pass.
The reason 25 versions is even possible at that intensity, from that author, is that the harness does the watching. Once the loop is set up, each iteration is "open a terminal, propose a hypothesis in plain English, glance at the dashboard, approve or revert." If anything, those two caveats are the strongest argument for building the harness: it converts the small windows of time a non-engineer actually has into shipped algorithm progress that would normally require a full-time CV engineer.