Harness engineering: the missing layer for reliable coding agents
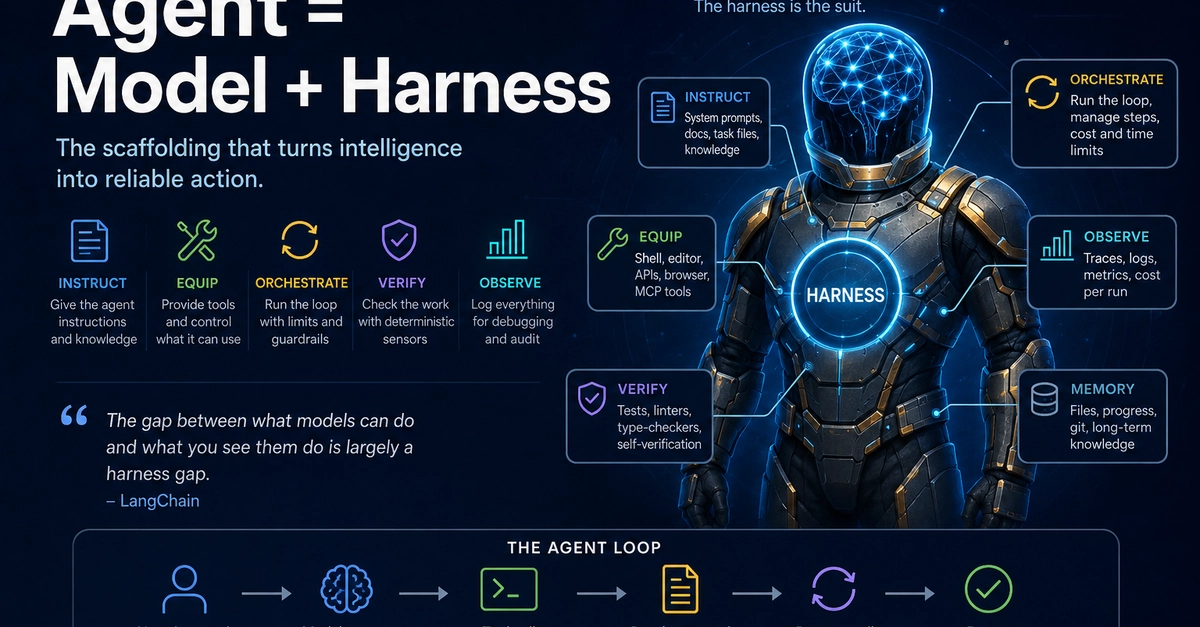
OpenAI’s recent discussion of harness engineering is a useful reminder that agentic coding is not just a model problem. Once an agent is allowed to work for hours, call tools, edit files, run tests, and make its own judgments, the quality of the surrounding system matters as much as the quality of the model itself. In that setting, prompts are only the starting point. The real question becomes: what environment do we build so the agent can work safely, consistently, and at reasonable cost?
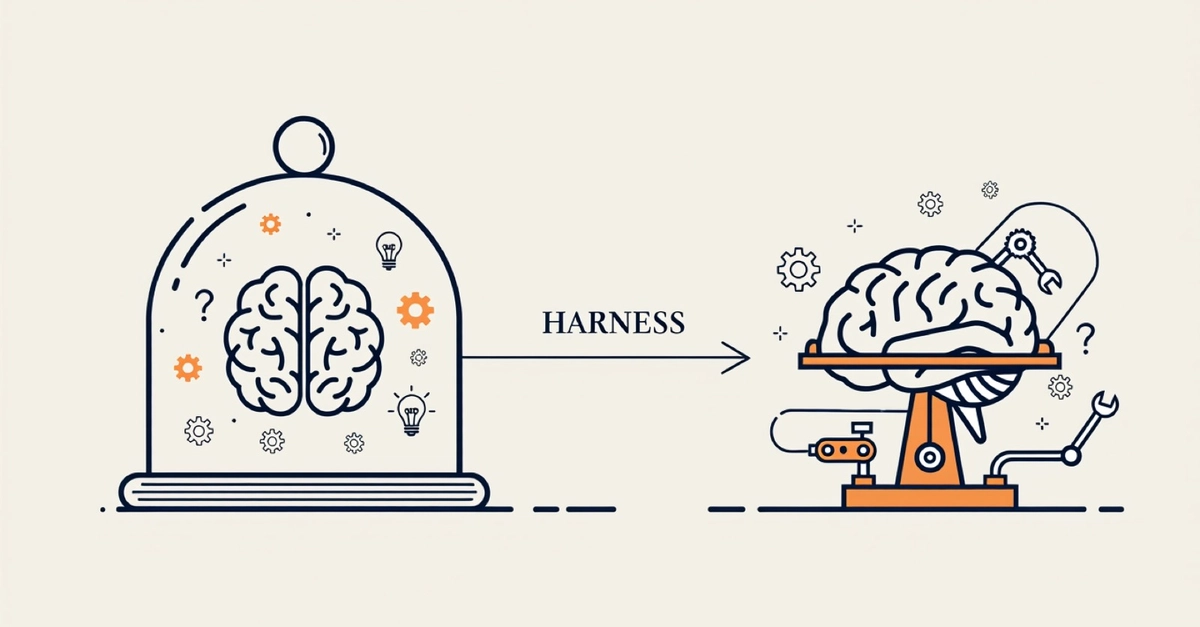
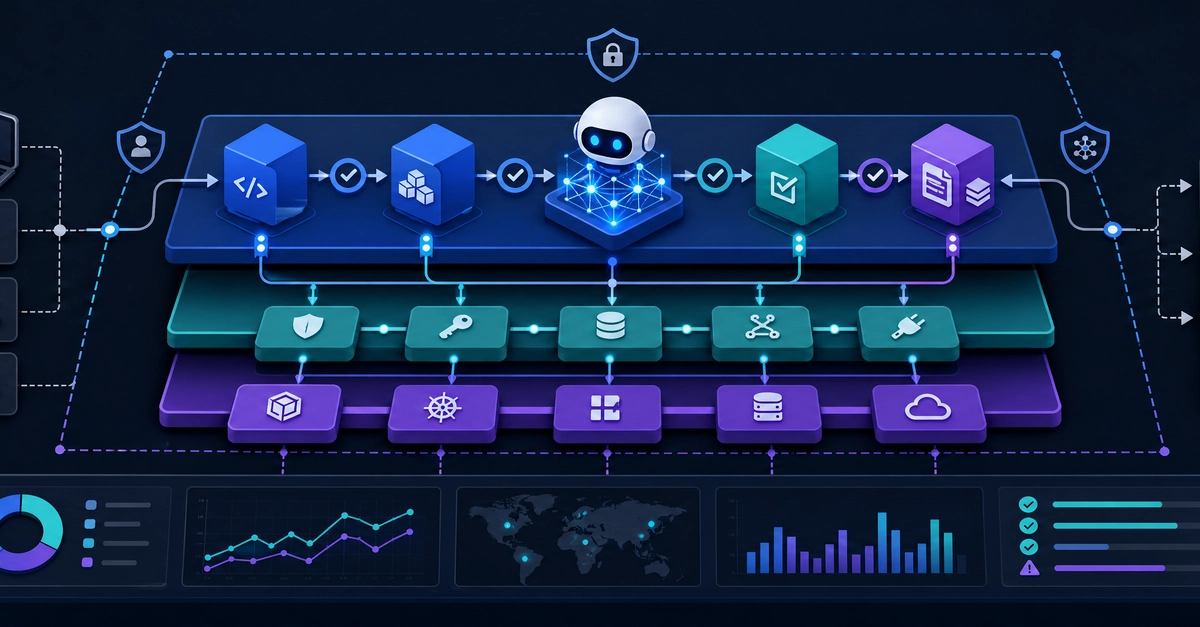
That is the core idea behind harness engineering. Instead of focusing only on prompting a model or stuffing more context into the window, you design the execution layer around the model: docs, tools, validation, architectural constraints, and feedback loops. In other words, you stop asking only “What should the model say?” and start asking “What should the model be allowed to do, how will it verify its work, and how will we keep it from drifting?”
Prompt engineering is not enough
Prompt engineering still matters. So does context management. But both of those approaches have a limited scope. Prompt engineering improves a single turn. Context engineering decides what the model can see in that turn. Harness engineering is different: it shapes the world the agent operates in over a long sequence of actions.