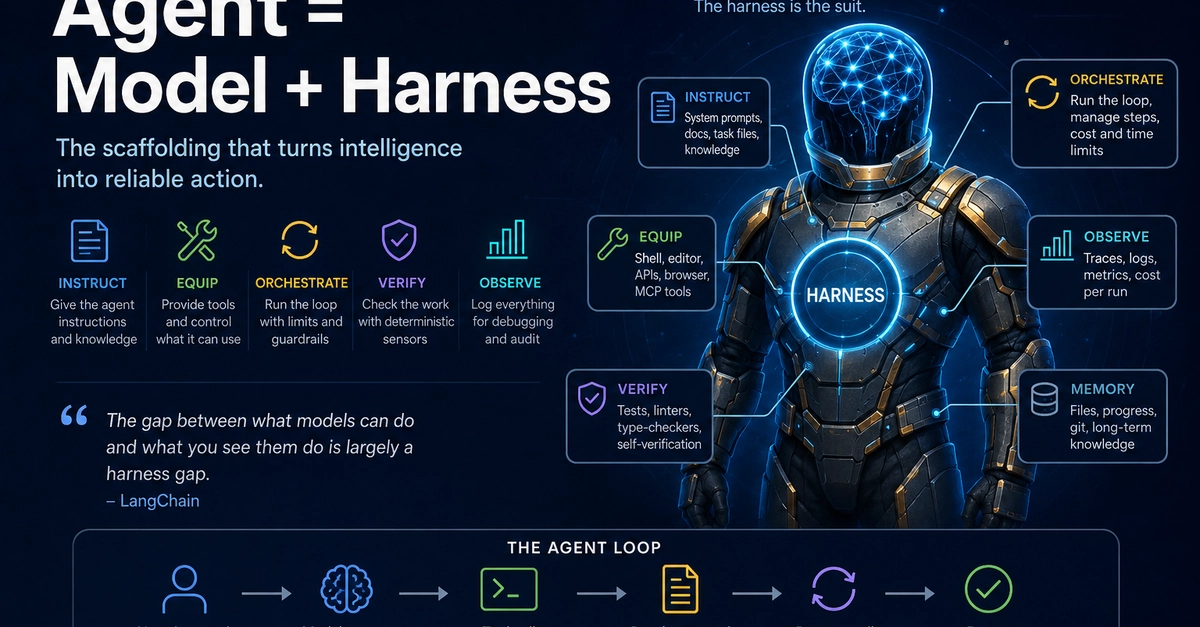
Not every company can or should build their own frontier AI language model. However, the harness controlling the model is something that most enterprises can and should customize for their specific purposes.Of course, this is easier said than done. Agent harnesses are still largely tuned through manual, ad hoc debugging — a process that relies heavily on intuition rather than systematic feedback loops, making it difficult to keep pace with rapidly evolving LLMs.To solve this challenge, researchers at the Shanghai Artificial Intelligence Laboratory have introduced “Self-Harness,” a new paradigm in which an LLM-based agent systematically improves its own operating rules. By examining its own execution traces to apply edits, the system trades manual guesswork for empirical evidence.Self-improving harnesses can enable development teams to deploy robust custom agents that continually adapt their own execution protocols to overcome model-specific weaknesses.The challenge of harness engineeringAn LLM-based agent's performance is not determined solely by its underlying base model, but also by its harness: the surrounding system that provides context and enables the model to interact with the environment. A harness includes components like system prompts, tools, memory, verification rules, runtime policies, orchestration logic, and failure-recovery procedures.This layer is crucial because many common agent failures stem from the harness rather than the model. For example, an agent may report success without checking the model’s response (e.g., running the code to see if it passes the tests), or it might retry a failed action repeatedly. The harness is also responsible for preventing context rot or overload when the agent’s interaction history grows very large. Examples of popular harnesses include SWE-agent, Claude Code, Codex, and OpenHands.Harness engineering remains a significant challenge, but the bottleneck isn't necessarily that humans are too slow or incapable. In fact, Hangfan Zhang, lead author of the Self-Harness paper, told VentureBeat that "in many cases, an experienced engineer with deep domain knowledge can still propose better changes than an LLM can today."Instead, the true bottleneck of manual engineering is that it relies heavily on ad hoc debugging rather than a verifiable, empirical feedback loop. "The deeper issue is that the current harness-engineering paradigm often lacks a systematic feedback loop," Zhang explained. "Many edits are made based on intuition, a few observed failures, or ad hoc debugging."With new models being released at a rapid pace, depending on human intuition to manually tune model-specific harnesses becomes increasingly costly and untenable. While some approaches use stronger models to improve the harnesses of weaker target agents, this dependence on external guidance has its own challenges, as these models may be costly, unavailable for frontier models, or mismatched to the target model's failure modes.How Self-Harness worksThe Self-Harness paradigm enables an LLM-based agent to improve its own harness without relying on human engineers or stronger external models.This continuous self-evolution is driven by a three-stage iterative loop that turns behavioral evidence into harness updates:Weakness mining: Starting from an initial harness, the agent runs a set of tasks, producing execution traces with verifiable outcomes. The agent categorizes failed traces and tries to detect model-specific failure patterns.Harness proposal: Based on these failure patterns, the agent uses a “proposer” role to generate a set of diverse yet minimal harness modifications, each tied to a specific failure mechanism to avoid overly general corrections.Proposal validation: The system evaluates candidate modifications through regression tests. An edit is promoted only if it improves performance without causing measurable degradation on held-out tasks. If multiple candidate modifications pass the regression tests, they are merged into the next version of the harness, which then serves as the starting point for the next iteration.Self-harness framework (source: arXiv)To visualize why an enterprise would need this, imagine an automated issue-fixing agent that reads internal documentation, writes patches, and opens pull requests. If the company updates its documentation style, the agent might suddenly fail, pulling the wrong context or writing bad patches. On the surface, the agent simply looks broken. But Self-Harness turns this ambiguous failure into a solvable problem. "The failure traces expose where the agent is misusing the new documentation format; the proposer can generate a targeted harness edit... and the evaluator can decide whether that edit improves the failing cases without regressing other cases," Zhang said.Self-Harness in actionThe researchers evaluated Self-Harness on Terminal-Bench-2.0, a benchmark that tests general tool-based execution, including artifact management, command use, verification behavior, and recovery from execution errors. They applied Self-Harness with MiniMax M2.5, Qwen3.5-35B-A3B, and GLM-5.To isolate the impact of the self-evolving harness, they started with a minimal harness built upon the DeepAgent SDK, containing only the benchmark-facing system prompt, and the default filesystem and shell tools. The model backend, tool set, benchmark environment, and evaluator were kept unchanged while only the harness was allowed to vary.The quantitative results show that agents improved their performance through automated harness edits. On held-out tasks, performance jumped significantly across the board, ranging from 33 to 60 percent relative improvements for different models.Self-harness allows agents to improve their own code and adapt it to the underlying model (source: arXiv)Importantly, an explicit acceptance rule promotes only those edits that improve performance without introducing unacceptable regressions. What makes Self-Harness powerful for enterprise applications is that it doesn’t simply make the prompt longer or add generic instructions. Instead, it introduces targeted changes that reflect the recurring problems each model encounters during execution.For example, under the baseline harness, MiniMax M2.5 would get stuck endlessly exploring dataset configurations until the execution environment timed out, failing to produce any deliverables. Through Self-Harness, the system identified this specific flaw and wrote a "loop breaker" into its runtime policy, forcing the agent to stop and redirect its approach after 50 tool calls. It also added a rule to create an initial version of required artifacts as early as possible.On the other hand, Qwen-3.5 had a habit of hitting a file overwrite error and then blindly retrying the same command repeatedly, eventually deleting necessary files out of confusion before stopping. The self-harness fixed this by introducing a strict command-retry discipline (forbidding exact duplicate commands) and a mechanism that forced the agent to immediately recreate any missing artifacts if a file error occurred.GLM-5 struggled to preserve environment changes across different commands, and would often waste time on massive downloads or finalize tasks even when sanity checks were failing. Its self-generated harness introduced rules instructing the agent to persist PATH variables across shell sessions, limit external compute, and repair any failed sanity checks before concluding its run.The hidden costs of automated harnessesWhile Self-Harness automates the tedious work of tracking down idiosyncratic model failures, decision-makers must be realistic about the trade-offs. Replacing human engineering with automated trial-and-error requires significant computational overhead."Self-Harness replaces part of the human engineering burden with repeated proposal generation, parallel candidate evaluation, and regression testing," Zhang said. "That can mean more API tokens, more latency during optimization, and more infrastructure for running evaluation tasks."Also, this system relies on the accuracy of its evaluation pipeline. During their experiments on Terminal-Bench-2.0, the researchers relied on strict, deterministic verifiers to ensure the agent's edits were actually helpful. Without this rigorous ground truth, an automated system risks promoting bad updates. "[The] evaluation system is not an optional component; it is what lets us trade human intuition for empirical evidence," Zhang said.This reliance on strict verifiers also dictates where Self-Harness should be deployed. "The best deployment targets today are environments where failures can be measured and where trial-and-error is relatively safe," Zhang said, pointing to coding, internal workflow automation, and DevOps data pipelines as ideal use cases.Conversely, enterprises should avoid fully automating harnesses in high-stakes or subjective fields. "The clearest red flags are domains where evaluation is subjective, delayed, non-deterministic, or costly to get wrong, such as medical decision-making, safety-critical infrastructure, or legal decisions."From prompt tweakers to feedback architectsThe introduction of self-improving agents does not mean coding or enterprise workflows will suddenly become human-free. The quality of collaboration between the human engineer and the AI is still paramount and difficult to capture with automated benchmarks. Instead, the engineering profession is moving up the abstraction layer. "The role of enterprise engineers will shift from manually patching individual prompts or tool calls toward designing the feedback systems that make agent improvement possible," Zhang predicted. Moving forward, "the engineer becomes less of a prompt tweaker and more of a feedback architect."As foundational models grow more capable, they will naturally absorb many capabilities that currently require manual harness engineering. "But once that happens, the harness will not disappear; its scope will move outward to connect the model to richer external environments," Zhang said. "Until that boundary moves beyond what humans can evaluate, humans will remain critical providers of feedback."
Researchers introduce Self-Harness, a framework that lets AI agents rewrite their own rules, boosting performance up to 60%
Moving beyond manual debugging, Self-Harness empowers AI agents to test, evaluate, and rewrite the very logic that governs their behavior.
1,431 words~7 min read