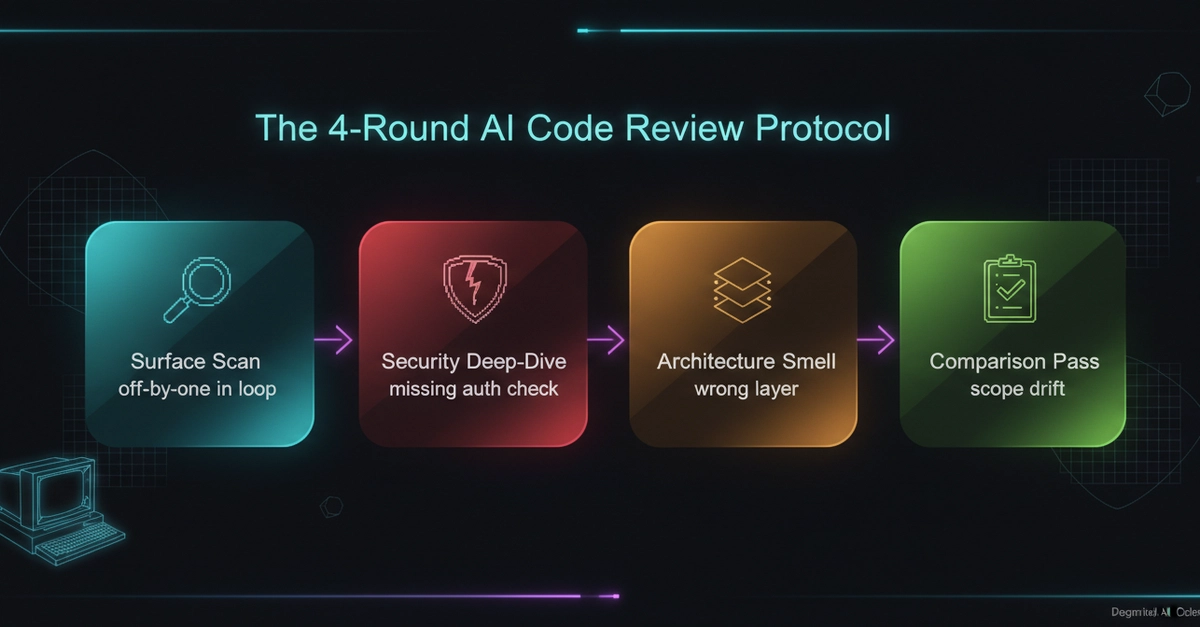
One night, two audits, one identical score
The evening of 17 May, I finish version 0.4.1 of the Counterpart Toolkit and decide to submit it to two external reviews. I paste the manifesto and the fourteen rules into a ChatGPT-4o session, then paste exactly the same content into a Claude.ai web session. I wait. A few minutes later, both verdicts land. Score 8/10 on one side. Score 8/10 on the other. Near-identical criticisms about the theoretical apparatus — Bourdieu invoked without operational traction — identical simplification suggestions, same angle on the freshness of the M1-M5 instrumentation. My initial reflex holds for thirty seconds. Two independent reviewers, same score, same criticisms — the doctrine is calibrated right, I can publish.
Then I stop. Because something in that convergence rings like a barometer bought in duplicate from the same supplier.
Why two converging AIs are not two measurements
I understand fairly quickly what the convergence is actually measuring. Two language models trained on corpora that overlap to a very large degree — technical articles, public GitHub repos, Stack Overflow discussions, a decade of blogs — produce correlated errors. What they have in common is their shared learning intersection, not the external reality I am submitting to them. When both find the theoretical apparatus disproportionate, I am not learning that it is true. I am learning that the shared statistics of their two corpora recognise this as a typical flaw in a text of this format.