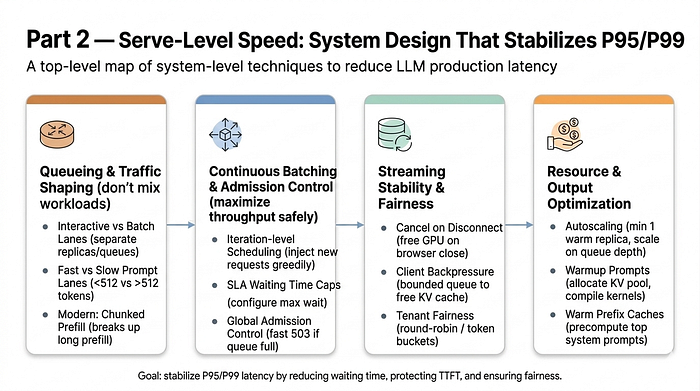
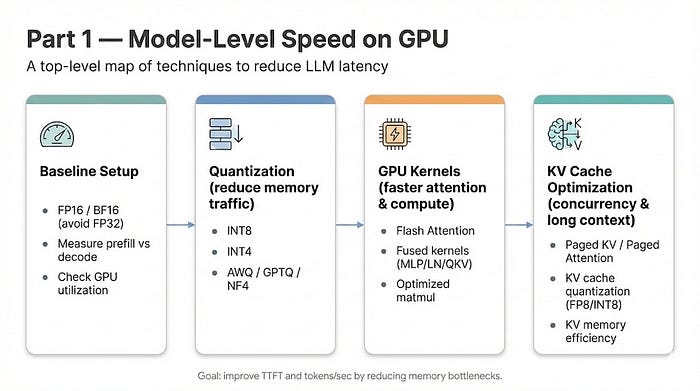
Modern LLM serving is hard to tune because each deployment is a stack of interacting choices: model backend, tensor-parallel shape, prefill/decode split, worker counts, scheduler settings, routing policy, KV cache behavior, autoscaling thresholds, and topology. Those choices interact across layers, and a local improvement can shift the bottleneck somewhere else. For larger models, even one realistic experiment can require many GPUs or nodes before we learn whether the idea was worth testing.
That is the motivation for DynoSim: a Dynamo twin.
DynoSim is a workload-driven discrete-event simulation of the NVIDIA Dynamo serving stack. It combines measured engine forward-pass timing, Mocker scheduler cores, Router, and Planner behavior, KV cache effects and workload traces on one virtual timeline. The goal is not a purely analytical estimate and not a bit-exact hardware emulator. The goal is a faithful serving simulation at the atomic level of forward passes, while extending up to the full inference stack, which for us is Dynamo (and for many others as well).
Not only is DynoSim faithful, it is also blazingly fast as a full-stack Rust implementation. On an Apple M4 MacBook Air, the single-threaded Rust offline replay simulated the full 23,608-request Mooncake trace with eight round-robin workers and 512-token trace and engine blocks in 2.41 seconds of wall time. The simulated serving window was 60.1 minutes, about 1,500x faster than real time.