Author(s): Mehedi Hasan
Originally published on Towards AI.
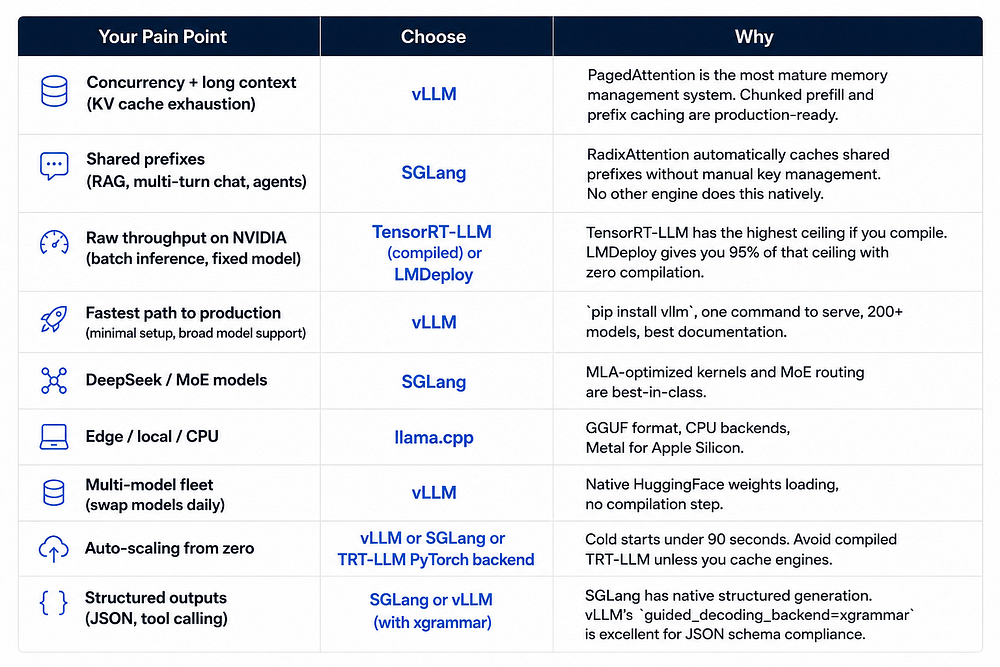
You’ve quantized the model, switched to Flash Attention, and maybe even dropped to INT4. Your GPU kernels are now efficient. But users still complain that the app is “sometimes slow.” Welcome to serving hell, where the bottleneck is rarely the model and almost always the system around it.
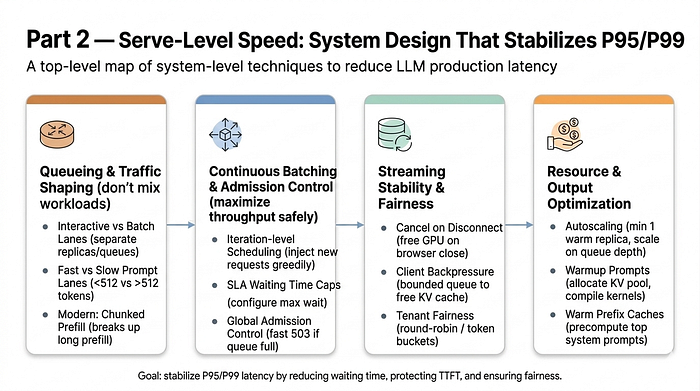
The theme of this part: once the model is efficient, most production wins come from queueing discipline, traffic routing, and stability controls. P95 and P99 latency are not driven by tensor core utilization. They’re driven by queueing, noisy neighbors, long prompts stuck behind short ones, and slow clients holding onto GPU memory.
System Level Techniques to reduce LLM production latency