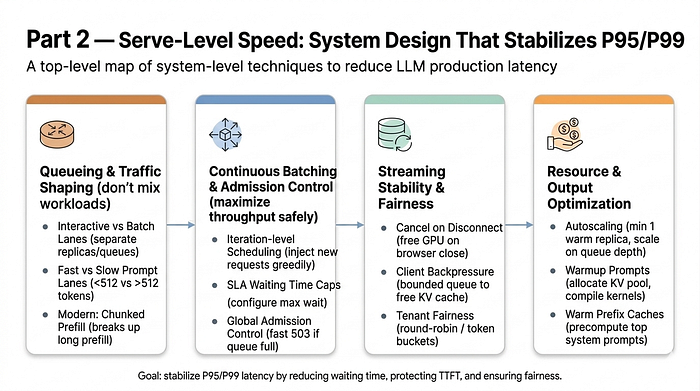
Look, I've been down this rabbit hole. You know that feeling when you're building a client app, and you think you've nailed the AI integration, but then the first user complains about lag? Yeah, been there. That's why I spent a weekend — yes, a whole Saturday — benchmarking 15 AI models on Global API's infrastructure.
Here's the thing: every millisecond of latency is a line item on your client's billable hours. If your chat app takes 2 seconds to start responding, that's not just bad UX. That's lost revenue. I've learned this the hard way, so let me save you the headache.
The Setup — Nothing Fancy, Just Real Data
I'm not a corporate lab. I'm a freelancer who needs models that work for clients without breaking the bank. So I tested these models like I'd test any tool for a side hustle: practical, repeatable, and obsessed with ROI.
Test parameters: