TODO: Remember to copy unique IDs whenever it needs used. i.e., URL: 304b2e42315e
Last Updated on June 3, 2026 by Editorial Team
Originally published on Towards AI.
Originally published at https://mhabir.substack.com.
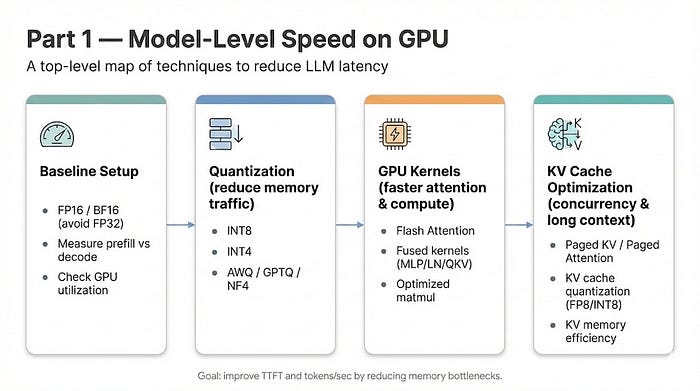
If you’re shipping LLMs to production, your first performance bottleneck isn’t serving logic or network overhead-it’s the raw arithmetic happening inside the GPU. Most teams waste weeks tuning their batching logic before realizing their model baseline is 3–4x slower than it should be. This part is about fixing that baseline.












