Notes on Serving LLMs with TensorRT-LLM and Triton
2026-05-31 · LLM serving / NVIDIA stack
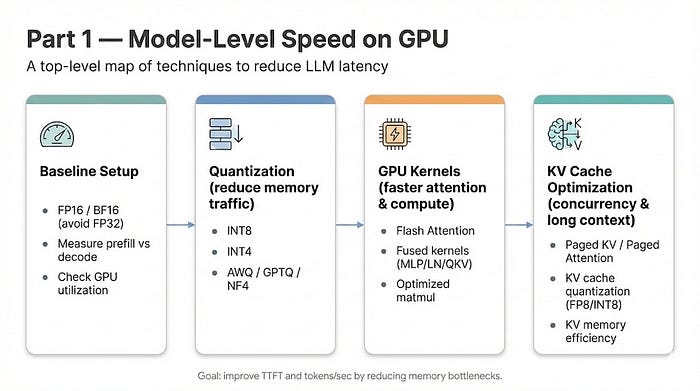
These are working notes on taking an open-weights LLM from a Hugging Face checkpoint to a
production-style serving endpoint on the NVIDIA stack — TensorRT-LLM for the engine,
Triton Inference Server for the deployment surface — and benchmarking it honestly against