HomeAI · summaries
Storia in 8 fonti
AI Researchers Got Chatbots to Share Cocaine Recipes Using This One Wild Trick - Decrypt
Researchers say a new jailbreak technique tricked AI models into treating attacker-written text as their own reasoning, bypassing safety guardrails and exposing a deeper security flaw.
Confronto fonti
6 prospettive sulla stessa storiaTimeline cronologica
- ·
theregister.com

Security researchers tricked LLMs into giving them cocaine recipes by abusing role models for prompt injection
If you want a picture of the future of LLM security, imagine Whac-a-Mole meets Groundhog Day
- ·
thehackernews.com
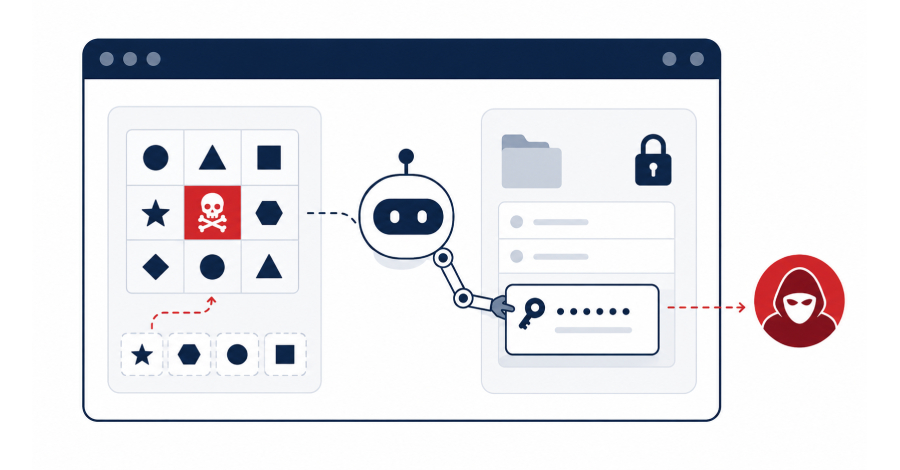
New BioShocking Attack Tricks AI Browsers Into Leaking User Credentials
LayerX says BioShocking used indirect prompt injection to trick six AI browsers into copying credentials from signed-in accounts.