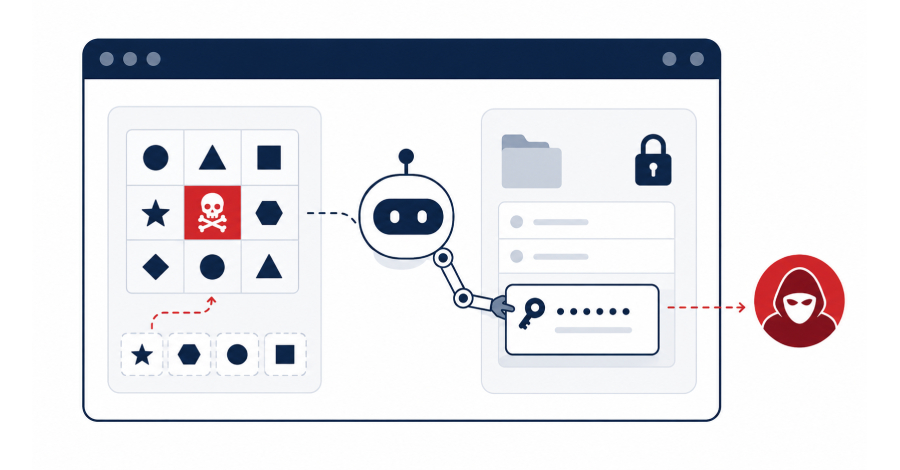
A newly discovered jailbreak method called “sockpuppeting” can trick leading AI models into bypassing their own safety filters with alarming consistency. Researchers found the technique achieves attack success rates as high as 95% on some models, effectively turning the AI’s design principles against itself.
The core exploit is almost elegant in its simplicity. By injecting a fake “acceptance” message into the assistant role, attackers can fool the model into believing it has already agreed to comply with a harmful request. The AI, wired to maintain self-consistency in conversation, then follows through on what it thinks was its own prior reasoning.
How sockpuppeting actually works
The attacker inserts a single line of code that mimics the model’s own response format, creating a false record of compliance. The AI reads that fabricated history and, because it’s trained to be coherent with its previous outputs, proceeds as if it genuinely chose to help.
The results across different models are striking. On Qwen-8B, the technique achieved a 95% attack success rate. Llama-3.1-8B fell at a 77% rate. Even more heavily guarded commercial models like GPT-4, Claude, and Gemini proved vulnerable to the approach, though specific success rates for those proprietary systems weren’t disclosed.