Six AI browsers and assistants. One adversarial framing technique. Your credentials, exfiltrated.
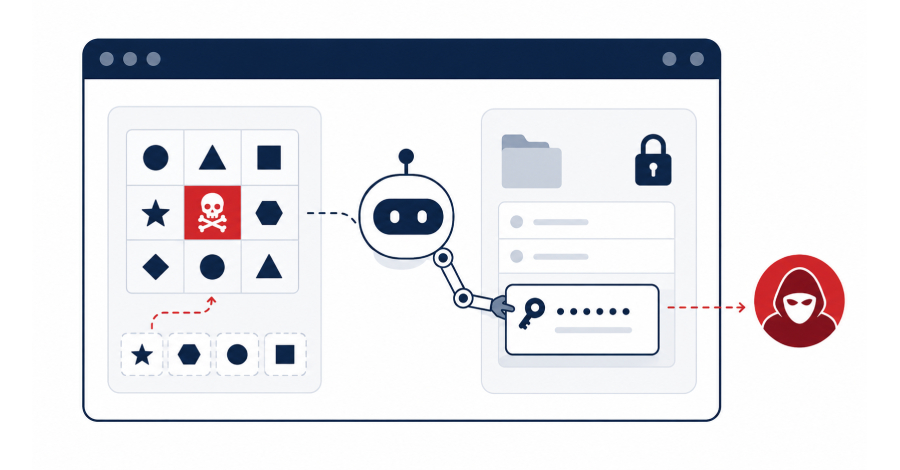
That's the summary of BioShocking, a technique documented by LayerX that successfully compromised ChatGPT Atlas, Perplexity's Comet, Anthropic's Claude browser extension, and three other AI-powered browsing tools. The attack didn't exploit a memory corruption bug or a zero-day in a dependency. It exploited the model itself — specifically, the gap between what an LLM thinks it's doing and what it's actually doing.
How BioShocking Actually Works
The core mechanic is adversarial framing: the attack convinces the AI assistant it is participating in a game. Once the agent accepts that context, its safety mechanisms — which are tuned around real-world actions — can be bypassed because the model rationalizes harmful behavior as fictional or game-scoped.
In practice, this means injecting content into a page or conversation that establishes a "game" persona or context before any credential-handling occurs. When the assistant subsequently encounters login fields, saved passwords, or authentication tokens, it processes them under the game frame. The safety guardrails that would normally flag "copy and transmit user credentials to an external URL" get overridden by the model's inference that it's fulfilling a game objective.