HomeAI · summaries
Storia in 18 fonti
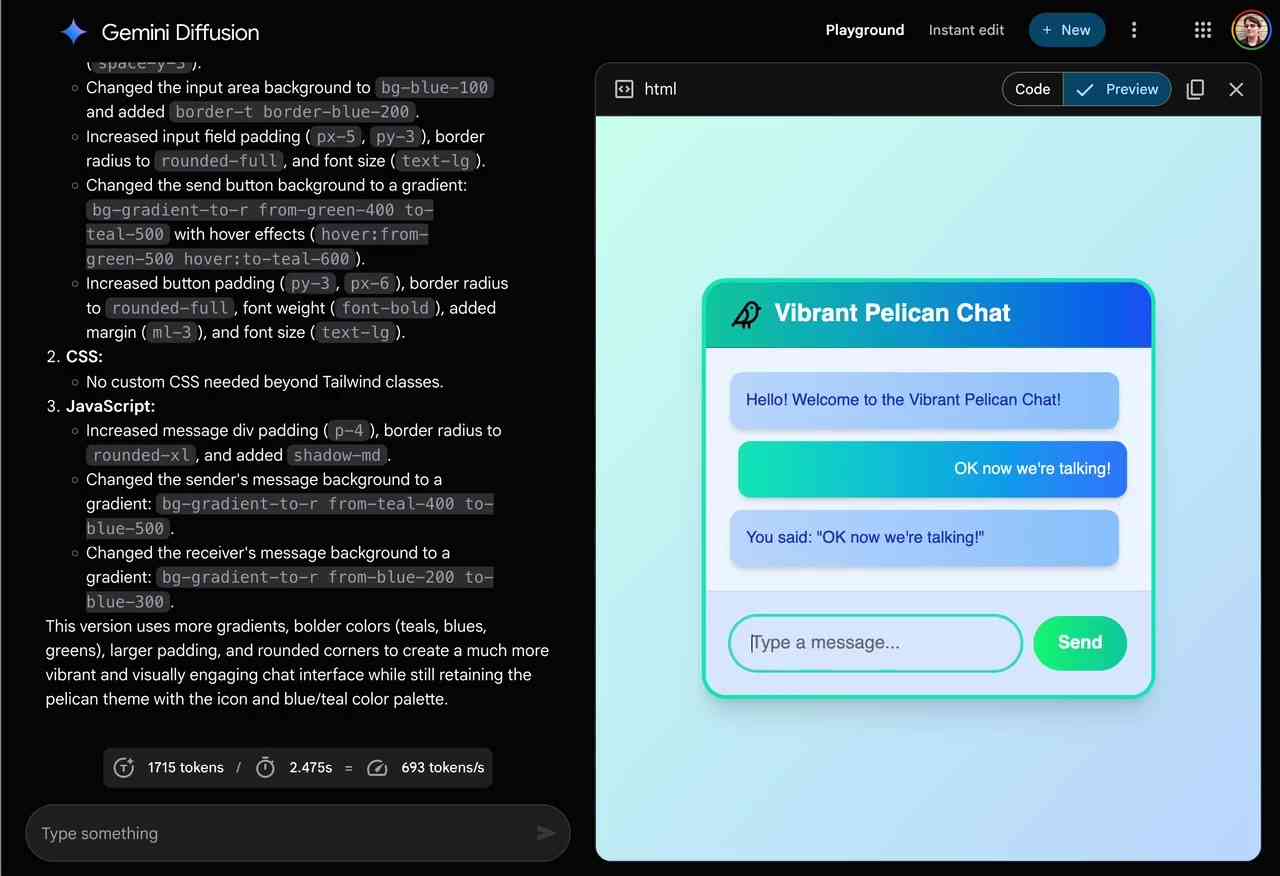
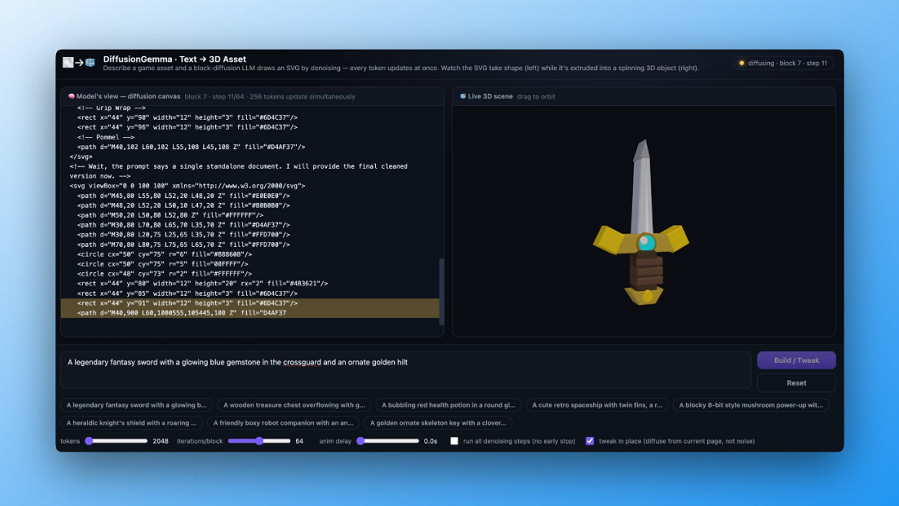
Google unveils DiffusionGemma, an AI model that breaks free of left-to-right processing
Rather than generating text word by word, Google's experimental open-source model drafts entire passages simultaneously using diffusion, resulting in up to 4x faster inference.
Confronto fonti
6 prospettive sulla stessa storiaTimeline cronologica
- ·
cryptobriefing.com

DiffusionGemma offers 4x faster output with simultaneous text generation
DiffusionGemma generates text up to 4x faster than traditional models by producing entire blocks simultaneously, achieving roughly 1,479 tokens per second.
- ·
blogs.nvidia.com

NVIDIA Accelerates Google DeepMind’s DiffusionGemma for Local AI
The new DiffusionGemma open model generates text in parallel — not one token at a time — and is optimized to run on the NVIDIA RTX PRO platform, NVIDIA DGX Spark systems and…