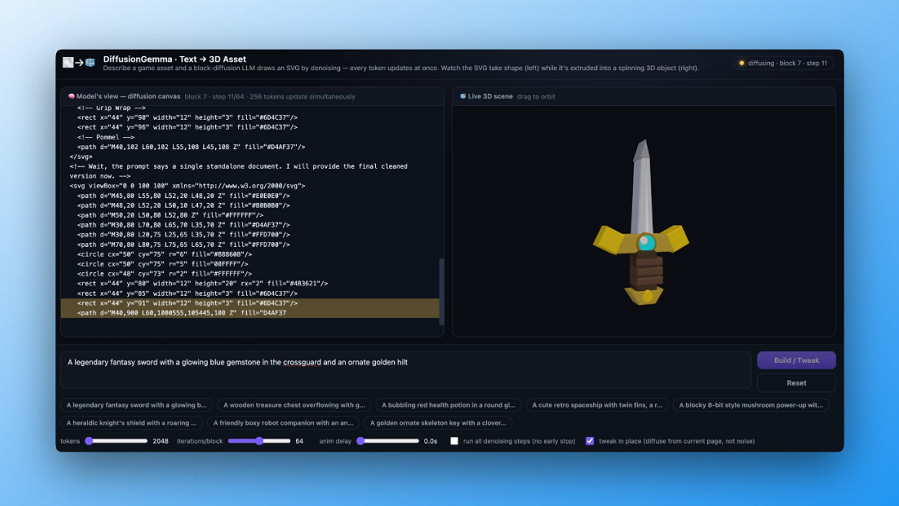
For years, large language models have worked like a very fast typist: one word at a time, left to right, no looking back. DiffusionGemma throws that playbook out entirely. The open model uses diffusion techniques to produce full blocks of text simultaneously, achieving generation speeds up to four times faster than traditional autoregressive models.
How DiffusionGemma actually works
Traditional language models generate text sequentially. Each token (roughly a word or word fragment) is produced one after another, with each new token depending on everything that came before it.
DiffusionGemma borrows from the same family of techniques that revolutionized image generation. Diffusion models work by starting with noise and iteratively refining it into coherent output. Applied to text, this means the model can work on multiple parts of a response at the same time rather than waiting for each word to be finalized before moving to the next.
In evaluations, DiffusionGemma has achieved sampling speeds of approximately 1,479 tokens per second. That 4x speed improvement isn’t a theoretical ceiling. It’s a measured benchmark.