
Jun 10, 2026
Our newest open experimental model delivers up to 4x faster inference on dedicated GPUs and opens the door to exploring speed-critical, interactive local workflows.
Brendan O'Donoghue
Research Scientist
Sebastian Flennerhag
An overview of DiffusionGemma, an exceptionally fast text generation model with up to 4x faster speeds.
Jun 10, 2026
Our newest open experimental model delivers up to 4x faster inference on dedicated GPUs and opens the door to exploring speed-critical, interactive local workflows.
Brendan O'Donoghue
Research Scientist
Sebastian Flennerhag

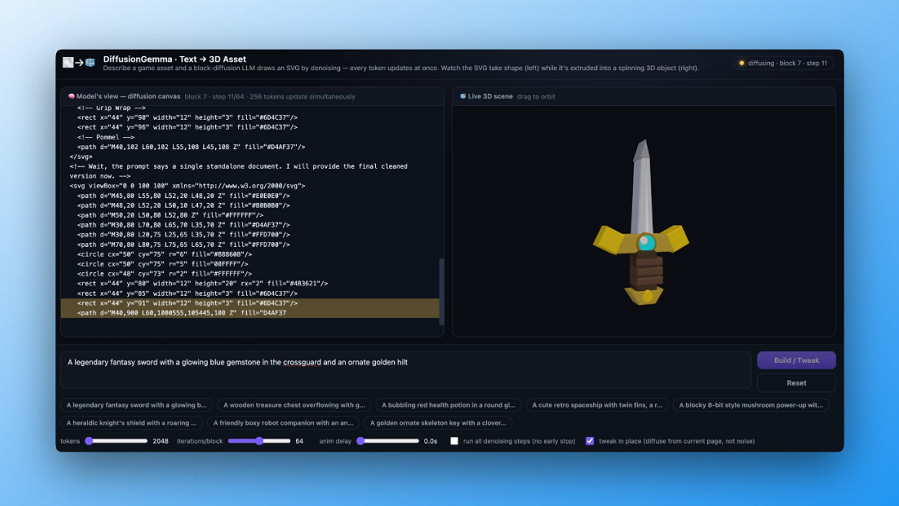
DiffusionGemma offers 4x faster output with simultaneous text generation

Google launches DiffusionGemma open model for faster local AI workflows

Google AI Releases DiffusionGemma, a 26B MoE Open Model Using Text Diffusion for Up to 4x Faster Generation

Google's latest DiffusionGemma open AI model comes with a 4x speed boost
Google open-sources speedy DiffusionGemma text diffusion model - SiliconANGLE

Run DiffusionGemma on NVIDIA for Developer-Ready, High-Throughput Text Generation | NVIDIA Technical Blog

Google's DiffusionGemma runs text 4x faster

DiffusionGemma: How Google's New Open LLM Hits 1,000 Tokens/sec and Changes Inference Economics

Google's new open model DiffusionGemma generates text from noise instead of word by word

Google's latest AI model creates text like an image generator
DiffusionGemma generates text up to 4x faster than traditional models by producing entire blocks simultaneously, achieving…
Google’s experimental DiffusionGemma model uses text diffusion to generate blocks of text in parallel, targeting faster local AI…
Google AI releases DiffusionGemma, a 26B MoE open text diffusion model generating 256-token blocks in parallel, up to 4x faster.
Diffusion AI is most common in image generation, but it can make text outputs much faster.
Google open-sources speedy DiffusionGemma text diffusion model - SiliconANGLE
Developers building real-time AI—such as chat assistants, copilots, and agentic workflows—are often constrained by token-by-token…