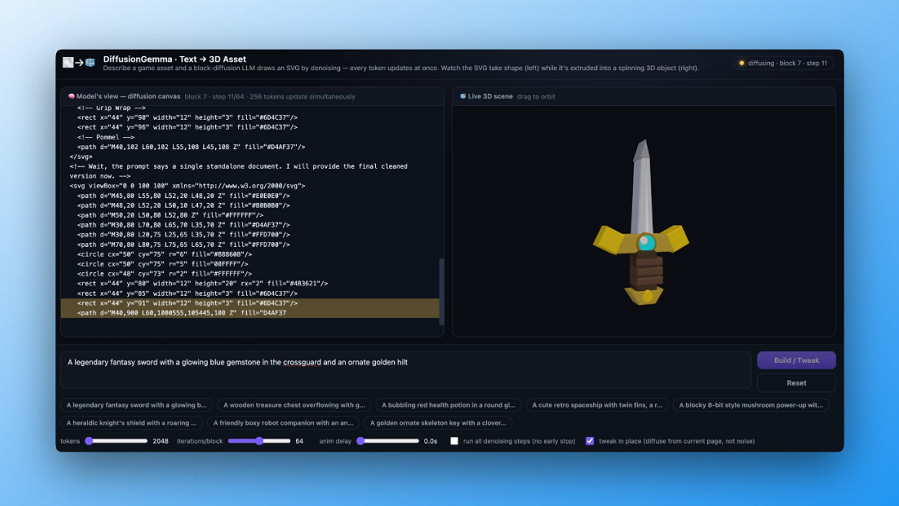
Google has introduced DiffusionGemma, an experimental open model designed to generate text faster by using diffusion instead of the token by token process behind most large language models.
DiffusionGemma is our new experimental open model with up to 4x faster output on dedicated GPUs.
Instead of predicting word-by-word, it generates entire blocks of text simultaneously. This lets the model self-correct and format complex markdown in real time. pic.twitter.com/S62OSbfWff
— Google DeepMind (@GoogleDeepMind) June 10, 2026
The model is a 26 billion parameter Mixture of Experts system released under an Apache 2.0 license. Google said DiffusionGemma activates only 3.8 billion parameters during inference and can run within 18GB of VRAM when quantized, making it suitable for high end consumer GPUs.